
Learn about some of the “best practices” for running a modern engineering organization that we practice at Cloud Posse. “Best Practices” are opinionated & proven strategies/tactics used to achieve some desired outcome.
These slides are a small part of what we think it takes to embrace a DevOps culture. It starts with the “Organization” embracing change and laying a foundation that will support the cross-disciplinary practice of DevOps.
Managing Secrets in Production
Secrets are any sensitive piece of information (like a password, API token, TLS private key) that must be kept safe. This presentation is a practical guide covering what we've done at Cloud Posse to lock down secrets in production. It includes our answer to avoid the same pitfalls that Shape Shift encountered when they were hacked. The techniques presented are compatible with automated cloud environments and even legacy systems.
The Paradigm Shift
Over the last year, we're seeing yet another massive transformation in how software is delivered take hold. I will call this a “Paradigm Shift” – containers are replacing virtual machines as the fundamental unit of software delivery at an unprecedented rate.
Over the last year, we're seeing yet another massive transformation in how software is delivered take hold. I will call this a “Paradigm Shift” – containers are replacing virtual machines as the fundamental unit of software delivery at an unprecedented rate.
Apparently, Moore’s Law applies to the rate of adoption of new technologies as much as it does the density of transistors. The adoption rate of public cloud adoption is twice that of what we saw with Virtual Machines, and now we're seeing the same thing with container adoption. Enterprises are interesting species to study because they are the slowest to move and therefore a consistent barometer of change. Enterprises are learning to be more tolerant of change—this an awesome trend.
What are the ingredients for a paradigm shift? Let’s begin by looking at a few examples.
The concept of “Virtual Machines” had been around since the 60s, but it took until the late 90s for the technology to catch up. It wasn’t until VMware came out with their “VMware Workstation” product in 1998 that the concept got popularized and we saw mass adoption. What did they do? They made it easy—first and foremost for developers to run multiple environments on their desktops. Then they conquered the enterprise with tools.
The other prime example is “Cloud Computing.” It was not a new concept, it’s just that no one had really cracked the nut to show us how to do it properly. That was until Amazon came along. With EC2 they made it accessible and showed us the possibilities; they let us write infrastructure as code. The possibilities blew our minds! So everyone tried to copy what Amazon did, but unfortunately, it was a little too late.
That's because now we have the container movement. The concept of “Containers” is also nothing new. In Linux, the core functionality has existed since 2008 when Google contributed their work on LXC – the technology behind containers – to the Linux Kernel. However, it wasn’t until Docker came along circa 2013 (5 years later!) and made it brain-dead easy for developers to run them that we started seeing an uptick in their adoption. Now Docker is taking a page out of VMware's playbook by following up with Enterprise tools for production with the release of the Universal Container Platform (“UCP”) & and the Docker Datacenter (“DDC”).
The secret?
- Make it easy.
- Target developers.
- Let percolate throughout the enterprise until resistance is futile.
In the wake of all these transitions is some collateral damage. These are shims or training wheels we used to get from bare metal to containers. It's the result of the natural process of innovation.
- A dozen or more hypervisor technologies like VMware, Zen, KVM will lose massive market share.
- Elaborate Configuration Management tools like Puppet and Chef that were created to address the broken ways we used to configure software (basically emulated what humans would do by hand) will no longer be needed because we don’t write software as broken anymore.
- EC2 private-cloud knockoffs like OpenStack, vCloud, Eucalyptus, CloudStack, etc that were designed to run your own private cloud on-prem like Amazon, now overkill or at the very least passé (R.I.P.)
So why is the move to containers happening so quickly?
Hint: It’s not strictly technological.
First, we can agree that the second iteration is easier, better, and faster than the first anytime we iterate. Simply put, everything is less scary the second time around. Moving from the classic “bare metal” paradigm to a “virtualized” one was a massive endeavor. It was the “first” major paradigm shift of its kind. It took convincing of both C-Level execs and wrangling of Operations teams. Since it was a foreign concept, there was severe skepticism and pushback at all stages. Flash forward 15 years later, and there’s now fresh blood at the top. There’s a new guard who has moved up through the ranks that’s more accepting of new technology. Enterprises have gotten better at accepting change. Moreover, the tools of the trade have improved. We’re better at writing software — software that is more cloud friendly (aka “cloud native”).
Here are my predictions for what we'll see over the next few years.
- Containers will become first-class citizens, replacing VMs as the defacto unit of the cloud.
- If you still need a VM, that’s cool; you’ll have a couple options:
- Leverage a VM running inside a container. There's a project by Rancher called “VM Containers” which does exactly this. Sound absurd? Not to Google. They run their entire Public Cloud – VMs & all – on top of Borg.
- Use Clear Containers by Intel which have minimal overhead, full machine-level isolation and can leverage the VT technology of modern CPU chipsets. Not to mention, it's fully Open Source!
- The brave will attempt using some sort of Unikernel, but it’s still too early to know for sure if that will be the way to go.
- Interest behind OpenStack (et al) will wane, and innovation will cease – they were ahead of their time. We learned A LOT from the experience – both what worked well and what didn't. As a result, we'll see a significant brain drain, with key contributors moving over to the Kubernetes camp.
- Kubernetes will replace OpenStack du jour and as a result we'll see a resurgence of bare-metal in the Enterprise
- Amazon’s ECS will be EOL’d and replaced with offerings of Kubernetes & Swarm.
- Kubernetes and Swarm will be battling it out for #1 because the competition is good.
- The best features of Mesos will be cherry-picked by both Kubernetes & Swarm, but Mesos will fail to gain a bigger foothold in the market.
Tips on Writing Go Microservices for Kubernetes
Kelsey Hightower, a Google Developer Advocate and Google Cloud Platform evangelist, recently gave a very helpful screencast demonstrating some of the tips & tricks he uses when developing Go microservices for Kubernetes & docker. Among other things, he recommends being very verbose during the initialization of your app by outputting environment variables and port bindings. He also raises the important distinction between readiness probes and liveness probes and when to use them. Lastly, in the Q&A he explains why it's advantageous to use resource files instead of editing live configurations because the former fits better in to a pull-request workflow that many companies already use as part of the CI/CD pipeline.
The 12-Factor Pattern Applied to Cloud Architecture

Heroku has deployed more services in a cloud environment than probably any other company. They operate a massive “Platform-as-a-Service” that enables someone to deploy most kinds of apps just by doing a simple git push. Along the way, they developed a pattern for how to write applications so that they can be easily and consistently deployed in cloud environments. Their platform abides by this pattern, but it can be implemented in many ways.
The 12-factor pattern can be summed up like this:
Treat all micro-services as disposable services that receive their configuration via environment variables and rely on backing services to provide durability. Any time you need to make a change it should be scripted. Treat all environments (dev, prod, qa, etc) as identical.
Of course, this assumes that the cloud-architecture plays along with this methodology for it to work. For a cloud-architecture to be “12 factor app” compliant, here are some recommended criteria.
1. Codebase
- Applications can be pinned to a specific version or branch
- All deployments are versioned
- Multiple concurrent versions can be deployed at the same time (e.g. prod, dev, qa)
2. Dependencies
- Service dependencies are explicitly declared and loosely coupled
- Dependencies can be isolated between services
- Services can be logically grouped together
3. Config
- All configuration is passed via environment variables and not hardcoded.
- Services can announce availability and discover other services
- Services can be dynamically reconfigured (E.g. using feature flags or changing environment)
4. Backing Services
- Services depend on object stores to store assets (if applicable)
- Services use environment variables to find backing services
- Platform supports backing services like MySQL, Redis or Memcache
5. Build, release, run (PaaS)
- Automation of deployments (build, release, run)
- All builds produce immutable images
- Deployment should result in zero down-time
6. Processes
- Micro-services should consist of a single process
- Processes are stateless and share-nothing
- Ephemeral filesystem can be used for temporary storage
7. Port binding
- Services should be able to run on any port defined by the platform
- Service discovery should incorporate ports
- Some sort of routing layer handles requests and distributes them to port-bound processes
8. Concurrency
- Concurrency is easily achieved by replicating the micro-service
- Scale automatically without human intervention
- Only sends traffic to healthy services
9. Disposability
- Services are entirely disposable (not maintain any local state)
- They can be easily created or destroyed
- They are not upgraded or patched (just redeploy!)
10. Dev/prod parity
- All environments function the same way
- Guarantees that all services in an environment are identical
- Code runs the same way in all places
11. Logs
- Logs treated as structured event streams (e.g. JSON) that can be subscribed to by multiple consumers
- Logs collected from all nodes in cluster and centrally aggregated for auditing all activity
- Alerts can be generated from log events
12. Admin processes
- It should never be necessary to login to servers to manually make changes
- APIs exist so that everything can be scripted
- Regular tasks can be scheduled to run automatically
Building a DevOps Culture
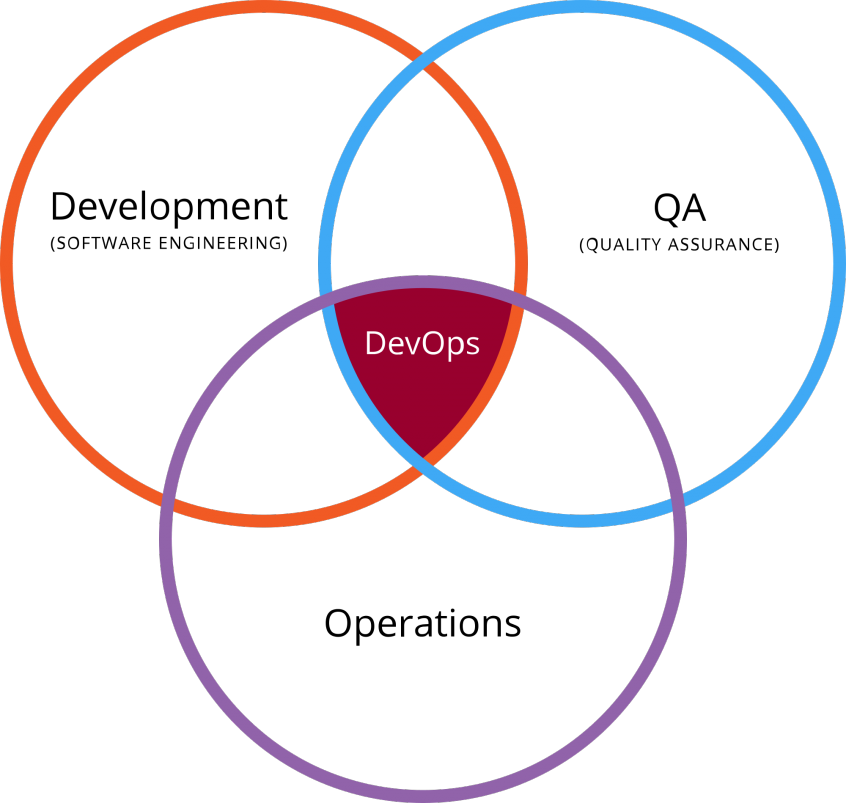
A question that often comes from well-established organizations with “mature” infrastructures is the following:
How can an organization instill a new engineering culture where developers and operations are working with each other and not against each other?
We affectionally call this “DevOps” movement; it's a culture where developers and ops work together and not against each other. Often their distinct roles are indistinguishable. Developers are confident on the command-line just as much as ops are confident in the IDE.
The key to succeeding with Devops is demonstrating to developers that it will actually make their job easier, such as when they can debug issues. Likewise, Ops needs to see the developers as a resource who can reduce the number of sleepless nights they experience as a result of failed deployments and buggy code. The role of ops in a DevOps culture is to enable devs to operate more efficiently. The role of devs in the organization is to build applications which are easily deployable.
Here’s what needs to happen. Ops needs to take a first step in standardizing the way software gets deployed. Start with taking a look at the current open source tools available. Choose one. Then they take those recipes and build a local development environment using something like Docker Compose or Vagrant so that developers can start getting familiar with it. Next, developers need to embrace the local dev environment over “native” environments (e.g. those that take a day of configuration and downloading packages). Through this process, they build up operational competency in debugging issues in environments that mirror production. After several months of operating like this, developers should shadow ops in certain roles, such as deploying software.
Once the above system is in place, the next step is to increase monitoring coverage and make this transparent to everyone in the org. In addition to your standard checks (like Nagios), you’re going to need to deploy something like DataDog or NewRelic. This gives your developers insights into how their apps are function in production and the necessary information to diagnose bugs. Tasks get created for every warning or error in production that is not handled in the proper manner. Once these alerts are calibrated to less than a few critical incidents per week, they should get wired up with PagerDuty. This is where the most resistance is usually encountered, but this is what keeps everything going. Without skin in the game, developers have no incentive make sure their code is highly reliable and ops are tied in what they can do to fix problems. But with only a few critical incidents, devs will be quickly motivated to fix the bugs and silence the alarms.
The last triumph in this conversion is to achieve “Continuous Integration” (CI) coupled with “Continuous Deployment”. Before this can even be remotely considered, considerable unit test coverage is needed. Stay tuned for more posts on these topics.