Basically, these sessions are an opportunity to get a free weekly consultation with Cloud Posse where you can literally “ask me anything” (AMA). Since we're all engineers, this also helps us better understand the challenges our users have so we can better focus on solving the real problems you have and address the problems/gaps in our tools.
Basically, these sessions are an opportunity to get a free weekly consultation with Cloud Posse where you can literally “ask me anything” (AMA). Since we're all engineers, this also helps us better understand the challenges our users have so we can better focus on solving the real problems you have and address the problems/gaps in our tools.
Basically, these sessions are an opportunity to get a free weekly consultation with Cloud Posse where you can literally “ask me anything” (AMA). Since we're all engineers, this also helps us better understand the challenges our users have so we can better focus on solving the real problems you have and address the problems/gaps in our tools.
Cloud Posse is the foremost DevOps Accelerator specialing in venture-backed tech startups up through F100 enterprises. This might sound like marketing hype to some, but it's our mission—it means so much more to us.
A “DevOps Accelerator” is a subcategory of Professional Services. It means that the provider has a proven, systematic, and repeatable process to help companies achieve a certain level of organizational “DevOps” maturity. The right accelerator for your business will have a similar ideology for how you would like to implement and run the technical operations of an organization. It will have demonstrated its ability to do this successfully for other businesses and will have tons of pre-existing materials that save you the cost of building it all from scratch. Some accelerators may require ongoing licenses and subscriptions, while others just give it away for free so that they can evolve at a faster rate by leveraging their community.
Working with an accelerator means you benefit from all their continuous learning across the various market segments they operate in. It means you benefit from their 20/20 hindsight—as your 20/20 foresight; you avoid all the common pitfalls associated with going it alone and instead get it right the first time and on time.
The Process
What does such a process look like? It starts with having a pre-existing project plan (e.g. in Jira) that takes a business through the journey of owning its infrastructure and includes the systems that go along with that, from beginning to end. It's much more than knowing how to write Infrastructure as Code (e.g. Terraform). It's knowing all the Design Decisions that go along with it so you can build a library of Architectural Design Records[1]https://docs.aws.amazon.com/prescriptive-guidance/latest/architectural-decision-records/architectural-decision-records.pdf. It's knowing the proper order of operations to execute it. And it's getting all the pieces to fit together across the various areas of your organization. It involves laying a solid foundation, building a platform on top of it to consistently run your services, creating a process to deliver your software consistently and reliably to that platform, and ensuring you have the observability and operational experience to drive it.
For some companies, it may also mean achieving various security benchmarks for compliance required to operate in their industry. Once this is all said and done, there needs to be a process to keep everything current and the ability to keep it up to date. There needs to exist materials for training, documentation, and knowledge transfer across the organization so that it sticks and doesn't become another failed initiative.
For example, for us, that means starting with your Foundational Infrastructure, which is how you manage your AWS Organization, divide up into different Organizational Units, and then segment workloads across accounts, VPCs, and subnets. A solid foundation is required for building anything, just like in the physical world. Without it, you end up with something like the Millenium Tower in San Francisco, which has a sinking problem [2]https://en.wikipedia.org/wiki/Millennium_Tower_(San_Francisco)#Sinking_and_tilting_problem. It doesn't matter how awesome or beautiful the architecture is on top of the foundation if it is at the mercy of what's beneath it.
A few of the considerations that need to be considered at the very beginning are how to operate in multiple regions, naming conventions, CIDR allocations, and so forth. Knowing your requirements for security & compliance is essential, so you get things right from the get-go, with minimal re-engineering efforts.
Build out your Platform
When you build out the platform, you decide how you want to deliver your services consistently. There are countless ways to go about this, but whatever the choice it has ramifications on how to do release engineering (e.g. CI/CD), the way applications are built, tested, and deployed, as well as how to achieve the subsequent benchmarks for compliance. A good platform will have just the right level of abstraction necessary to standardize the delivery without obfuscating how everything works and limiting the business's ability to capitalize on new trends.
A common pitfall is that companies prematurely attempt to abstract too much of their platform before they have the real-world experience to have an educated opinion on it. The wrong platform can have just as much of a detrimental effect on the business as a good one. A smaller business should be weary of emulating the platforms used by massively successful companies like Netflix and Spotify which have legions of engineers supporting them. Instead, they need to focus on a nimble platform that isn't too trendy but isn't so limited that all business value is lost.
Working with a DevOps Accelerator will ensure you get the right amount of platform for the stage you are at today. While things like a Service Mesh are tremendously advantageous for one business, it can be the Achilles Heel of the next if they don't have the in-house expertise to leverage it.
Rollout Shared Services
Once the platform is in place we're ready to deploy the shared services that are needed before we begin delivering applications on top of the platform. Businesses commonly require things like self-hosted CI/CD runners (e.g. for GitHub Actions), GitOps toolings like Atlantis or Spacelift, or observability tools like Datadog. These are part of the shared services layer because they extend the platform's capabilities.
Deploy your Applications
Modern engineering organizations are polyglots as a result of evolving with the times. They'll have something like a React frontend, with a service-oriented backend architecture consisting of Go-microservices, legacy rails apps, and maybe some high-performance rust microservices services, etc. We can never assume that the software development trends and landscape will remain the same. That's why when we work with customers to implement their Release Engineering patterns, we implement the reusable workflows and composable GitHub Actions that make build-test-and-deploy consistent and straightforward for every language, framework, and platform. We treat CI/CD as an interface for delivering your applications; therefore it must be consistent and repeatable.
Achieve Benchmark Security & Compliance
Security and Compiance is as much a technical need as a strategic business advantage. Frequently our customers want to outmaneuver their competition by achieving various benchmarks of compliance so they can land bigger deals or use it as a major differentiator when compared to their competition. Amazon understands this, which is why they offer an entire suite of security-oriented products that make achieving compliance easier. We've implemented native support for this in Terraform as part of our Security and Compliance offering which is available as part of our Reference Architecture for AWS.
Alternatives
Many more approaches are commonly taken when building out the infrastructure and platform for a business. These approaches may sound familiar, as well as the problems associated with them. Maybe the DevOps Accelerator route is for you if you've tried any of them and failed.
Build it all In-House
By in large most companies build their infrastructure using entirely in-house resources. They either pull from their existing talent pool or hire a team to build it. The advantage is that the business may think it knows exactly what it needs, so it starts building it immediately. It's a rewarding process for engineers because developers are inventive, natural creators who love to build new things.
To go this route, the business must allocate a budget, pull the resources aside to focus entirely on building out the next generation of its platform, and then construct the plan for getting there.
The risk is that the company hasn't done this before. While the team is smart and accomplished, they lack the end-to-end plan for getting there and likely underestimate the time & effort required to complete the project. In engineering, it's all too common for engineers to underestimate the level of effort required and the impact of distractions on timelines, so we overestimate the likelihood of succeeding the first time we implement anything.
Hofstadter's Law: It always takes longer than you expect, even when you take into account Hofstadter's Law.[2]
More commonly, we see that the engineers get pulled back into firefighting mode. Now the business has two problems. Maintaining the old infrastructure while attempting to innovate on the new infrastructure while exhausted from fighting fires.
Once you've built this shiny new infrastructure, it moves into the second stage: maintenance. This is a boring phase compared to the stage of building it. We see many companies hemorrhage employees, once the infrastructure is built because the fun is over; the company is left holding the bag, and the persons who built it may no longer be there to maintain it.
On the other hand, working with a DevOps Accelerator means you have the plan already in place, and the plan has been vetted and iterated on with each implementation executed by the DevOps Accelerator. This continual learning leads to a better outcome with less risk. The time estimates will be more accurate; the outcome will be guaranteed upfront. Everything is always better on the second iteration. Imagine that a DevOps Accelerator performs the same work, a dozen or more iterations per year.
Hire an Independent Contractor
This relatively safe and proven path works well for smaller businesses whose infrastructure requirements are satisfied by the output of a sole individual. Independent Contractors are the best choice when you have a small project and know what you need. You can often negotiate better rates when working directly with a freelancer since there are no middlemen. Other times, companies hire contractors directly because the relationship is so successful.
It can be problematic, however, since as a business you have legally no control over when or how the Independent Contractor performs the work. They are an independent business and under the law, need to operate like a business and have multiple customers. Customer demands are unpredictable, project scopes can easily explode unexpectedly in scope, and life's surprises can pull them away from your project. The best contractors will want to please all their customers, but this can easily overwhelm them if the demands exceed their capacity.
You also must be aware of laws in your jurisdiction working with Independent Contractors. Many states are beginning to tighten their laws around working with Independent Contractors and using California as an example.
California AB5 Law
California is very strict on this under the AB5 law[3]https://www.dir.ca.gov/dlse/faq_independentcontractor.htm. Most companies' understanding of how AB5 works are outdated, as the law was re-interpreted in 2019 [4]Vazquez v. Jan-Pro Franchising International, Inc. that Dynamex, which means how it is enforced is retroactive to the date the law was originally introduced. If Independent Contractors do not pass the ABC test, they may be considered employees under the law, and there's no amount of contract language that can circumvent it or prevent it. All that matters is where the work is performed; if you are a California company or the Independent Contractor is based in California, the state will claim jurisdiction. The longer you work with the Independent Contractor, the greater the risk that they will be classified as an employee. The worst part is that there are almost no consequences for the Independent Contractor, so the hiring entity bears all financial risks. There's almost no way for a business to verify that an Independent Contractor meets the “Business Services Provider” criteria of the AB5 law, and many Independent Contractors are unaware of how this law works. As of 2020, the California EDD resumed all payroll tax audits targeting the 2 million independent contractors in California [5]https://www.prnewswire.com/news-releases/ca-edd-confirms-it-has-resumed-tax-audits-relating-to-the-misclassification-of-10-million-contractors-301125947.html.
Working with an established DevOps Accelerator eliminates these risks. The DevOps Accelerator is responsible for complying with all local employment laws. It handles all the staffing and business continuity issues and has the preexisting materials ready to perform the implementation. The hiring company can continue to focus on its core product rather than get distracted by implementing its next-generation infrastructure and platform, a non-core competency of the business. When the project completes, the hiring company can scale back on the services from the accelerator or scale back later if it needs more help. It offers the best of both forms of engagement.
Partner with a DevOps Professional Services Company
Our industry is ripe with Professional Services Companies (thousands of them) that will work closely with you to implement a fully custom solution that meets exactly your requirements. The first obstacle encountered is deciding on which one to go with when every one of them claims they are the industry leader. You might reach out to your AWS Account Representative to ask for some referrals, and they'll have recommendations for AWS Partners that are a good fit for your stage. Working with a major professional services company might be the safest option—you'll avoid the risks of working with an independent contractor, but it's fraught with problems.
The first challenge is how to vet them and their solution. They'll almost always say they can't show you what it looks like because their work is confidential and protected by an NDA between them and their clients. That's fair, but it still puts the buyer at the disadvantage of not knowing what you're buying before you commit. So instead, you'll need to rely on Case Studies, if they even have them, which are wonderful but sell a pretty picture of the outcome but not all the dirty details.
Throughout this process, you'll mostly talk with sales reps and account managers. You'll be frustrated with their explanations' hyperbole, flashy pitch decks, and lack of technical detail if you're a technical organization. You'll have little knowledge of who you'll actually be working with, and chances are they'll take a junior engineer and mark them up 2-4x. It's a profitable business for them, but you're left ultimately holding the bag: custom infrastructure built for you might sound great, but it's a hornet's nest to maintain in the long run. Of course, this is what they hope for so that there'll be a steady stream of follow-up work. As a result, these sorts of projects cost way more than budgeted.
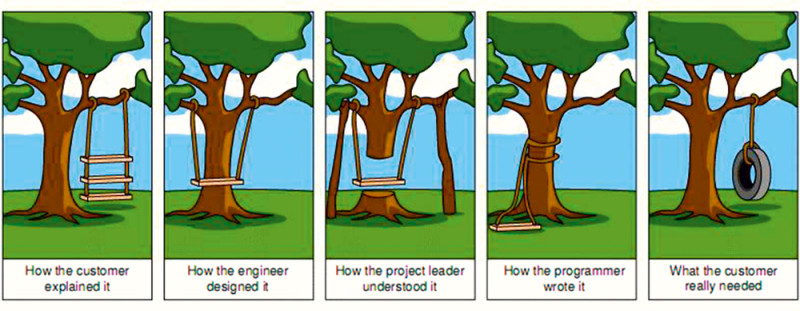
Pitfalls of Custom Software Development [6]https://the-innovator.club/index.php/2020/11/09/what-happens-when-what-you-deliver-is-not-what-the-customer-expected/
While the professional services company may have a library of case studies, it doesn't mean they have a repeatable process. On top of that, they may be reimplementing everything for you unless they bring materials, which is reinventing the wheel every time; each implementation is a snowflake that will stop evolving when the contract ends. Any continued learning by the professional services company will not be passed along to you.
Contrast that with working with a DevOps Accelerator. The accelerator will have a proven, documented process that they follow every time, ensuring consistent results without creating unmaintainable snowflakes. They can show you exactly what you will get before you begin.
You should expect to receive live demos as part of the presales process, with clear and concise answers on what exactly you will receive — less handwaving and no fancy PowerPoint presentations. You should meet directly with highly technical engineers and skip all the b.s. sales mumbo-jumbo that makes developers roll their eyes.
Their solution will not be conveniently gated behind confidentiality agreements. The best accelerators will leverage large amounts of Open Source as a licensing and distribution model ensuring that you do not miss out on all the continued learnings and are not on the hook for expensive ongoing license fees. It's like buying and owning a Tesla; you continually receive free upgrades that increase the longevity of your investment by providing free Over-the-Air (OTA) upgrades that contain bug fixes and enhancements.
Outsource It
Outsourcing is probably the most economical way of building out your infrastructure, but it's fraught with risk. In the risk/reward paradigm, you are rewarded for taking bigger risks when they pay off, but you need to know what you're doing. Do not outsource your cloud architecture and its implementation to the same partner unless you have the in-house expertise to validate everything delivered to you one pull request at a time. Be very cautious if you don't know what you need because you may be sold something that will simply need to be redesigned at the next stage of your growth. Make sure all the work is performed in repositories you control, with regular commits and demonstrated functionality. Don't sign off on anything until you've seen it in action. Also, be advised that it's almost impossible to conduct meaningful background checks in many foreign countries. It's almost impossible to enforce contract terms; if you need to, it will be very costly and conducted in unfamiliar jurisdictions.
On the flip side, when you work with an onshore DevOps Accelerator, you buy a known quantity – a working solution that you can vet before starting. You have the peace of mind of knowing that if anything goes seriously wrong, you have recourse; the provider should guarantee their work and carry sufficient insurance to do the work they perform. The services provider will know how their solution scales as your business evolves and will continually invest in the solution, which benefits the buyer over the long term.
Use a Managed Services Provider (MSP)
Working with a Managed Services Provider makes sense if you're a nontechnical organization and there's no sense in understanding or knowing how your infrastructure works. Your business has no competitive advantage in controlling all the toggles, and you have very few opinions on how it gets done or implemented. This is powerful when you can focus entirely on delivering your product, and you're not held up on the minutia of infrastructure.
The problem is that it's like “outsourcing” what should be your industry competitive advantage. While it may make a lot of sense to outsource transactional areas of your business like HR and accounting, infrastructure relates to your product. When you adopt the DevOps methods, you are leveling the business up across multiple divisions, enabling you to be nimble and rapidly respond to market trends. That's why this method will fail in the long run, even with initial success. Remember, most “Case Studies” are conducted immediately after a project's implementation, the time at which it's most likely to be successful; they are not longitudinal studies on how the solution performs years later.
In the DevOps Accelerator model, you have the benefits associated with working together with an MSP without the risks of outsourcing your advantage. They will work directly with you to ensure you have everything you need to own and operate your infrastructure – including infrastructure as code, documentation, and processes for day-2 operations. They will remain engaged even after the initial scope of work is completed and provide you with the ongoing support you need until you have the operational excellence to do it all yourself. Because you own this business area, the methods become part of your processes. These will evolve and become the strategic advantage you need in a competitive market landscape, enabling you to phase shift and out-tack your competition.
Next Steps
If you're curious about what benefits may await you working with a DevOps Accelerator, we encourage you to reach out. You can expect a refreshingly different experience. No hungry sales reps. Just an honest review of your problems with an experienced, highly technical cloud architect who can demonstrate with live examples how we can address them using our proven process.
Basically, these sessions are an opportunity to get a free weekly consultation with Cloud Posse where you can literally “ask me anything” (AMA). Since we're all engineers, this also helps us better understand the challenges our users have so we can better focus on solving the real problems you have and address the problems/gaps in our tools.
This new module can be used very simply, but under the hood, it is quite complex because it is attempting to handle numerous interrelationships, restrictions, and a few bugs in ways that offer a choice between zero service interruption for updates to a security group not referenced by other security groups (by replacing the security group with a new one) versus brief service interruptions for security groups that must be preserved. Another enhancement is now you can provide the ID of an existing security group to modify, or, by default, this module will create a new security group and apply the given rules to it.
Avoiding Service Interruptions
It is desirable to avoid having service interruptions when updating a security group. This is not always possible due to the way Terraform organizes its activities and the fact that AWS will reject an attempt to create a duplicate of an existing security group rule. There is also the issue that while most AWS resources can be associated with and disassociated from security groups at any time, there remain some that may not have their security group association changed, and an attempt to change their security group will cause Terraform to delete and recreate the resource.
The 2 Ways Security Group Changes Cause Service Interruptions
Changes to a security group can cause service interruptions in 2 ways:
Changing rules may be implemented as deleting existing rules and creating new ones. During the period between deleting the old rules and creating the new rules, the security group will block traffic intended to be allowed by the new rules.
Changing rules may be implemented as creating a new security group with the new rules and replacing the existing security group with the new one (then deleting the old one). This usually works with no service interruption when all resources referencing the security group are part of the same Terraform plan. However, if, for example, the security group ID is referenced in a security group rule in a security group that is not part of the same Terraform plan, then AWS will not allow the existing (referenced) security group to be deleted, and even if it did, Terraform would not know to update the rule to reference the new security group.
The key question you need to answer to decide which configuration to use is “will anything break if the security group ID changes”. If not, then use the defaults create_before_destroy = true and preserve_security_group_id = false and do not worry about providing “keys” for security group rules. This is the default because it is the easiest and safest solution when the way the security group is being used allows it.
If things will break when the security group ID changes, then set preserve_security_group_id to true. Also read and follow the guidance below about keys and limiting Terraform security group rules to a single AWS security group rule if you want to mitigate against service interruptions caused by rule changes. Note that even in this case, you probably want to keep create_before_destroy = true because otherwise, if some change requires the security group to be replaced, Terraform will likely succeed in deleting all the security group rules but fail to delete the security group itself, leaving the associated resources completely inaccessible. At least with create_before_destroy = true, the new security group will be created and used where Terraform can make the changes, even though the old security group will still fail to be deleted.
The 3 Ways to Mitigate Against Service Interruptions
Security Group create_before_destroy = true
The most important option is create_before_destroy which, when set to true (the default), ensures that a new replacement security group is created before an existing one is destroyed. This is particularly important because a security group cannot be destroyed while it is associated with a resource (e.g. a load balancer), but “destroy before create” behavior causes Terraform to try to destroy the security group before disassociating it from associated resources so plans fail to apply with the error
Error deleting security group: DependencyViolation: resource sg-XXX has a dependent object
With “create before destroy” set, and any resources dependent on the security group as part of the same Terraform plan, replacement happens successfully:
New security group is created
Resource is associated with the new security group and disassociated from the old one
Old security group is deleted successfully because there is no longer anything associated with it
(If a resource is dependent on the security group and is also outside the scope of the Terraform plan, the old security group will fail to be deleted and you will have to address the dependency manually.)
Note that the module's default configuration of create_before_destroy = true and preserve_security_group_id = false will force the “create before destroy” behavior on the target security group, even if the module did not create it and instead you provided a target_security_group_id.
Unfortunately, creating a new security group is not enough to prevent a service interruption. Keep reading for more on that.
Setting Rule Changes to Force Replacement of the Security Group
A security group by itself is just a container for rules. It only functions as desired when all the rules are in place. If using the Terraform default “destroy before create” behavior for rules, even when using create_before_destroy for the security group itself, an outage occurs when updating the rules or security group because the order of operations is:
Delete existing security group rules (triggering a service interruption)
Create the new security group
Associate the new security group with resources and disassociate the old one (which can take a substantial amount of time for a resource like a NAT Gateway)
Create the new security group rules (restoring service)
Delete the old security group
To resolve this issue, the module's default configuration of create_before_destroy = true and preserve_security_group_id = false causes any change in the security group rules to trigger the creation of a new security group. With that, a rule change causes operations to occur in this order:
Create the new security group
Create the new security group rules
Associate the new security group with resources and disassociate the old one
Delete the old security group rules
Delete the old security group
Preserving the Security Group
There can be a downside to creating a new security group with every rule change. If you want to prevent the security group ID from changing unless absolutely necessary, perhaps because the associated resource does not allow the security group to be changed or because the ID is referenced somewhere (like in another security group's rules) outside of this Terraform plan, then you need to set preserve_security_group_id to true.
The main drawback of this configuration is that there will normally be a service outage during an update because existing rules will be deleted before replacement rules are created. Using keys to identify rules can help limit the impact, but even with keys, simply adding a CIDR to the list of allowed CIDRs will cause that entire rule to be deleted and recreated, causing a temporary access denial for all of the CIDRs in the rule. (For more on this and how to mitigate against it, see The Importance of Keys below.)
Also, note that setting preserve_security_group_id to true does not prevent Terraform from replacing the security group when modifying it is not an option, such as when its name or description changes. However, if you can control the configuration adequately, you can maintain the security group ID and eliminate the impact on other security groups by setting preserve_security_group_id to true. We still recommend leaving create_before_destroy set to true for the times when the security group must be replaced to avoid the DependencyViolation described above.
Defining Security Group Rules
We provide several different ways to define rules for the security group for a few reasons:
Terraform type constraints make it difficult to create collections of objects with optional members
Terraform resource addressing can cause resources that did not actually change to be nevertheless replaced (deleted and recreated), which, in the case of security group rules, then causes a brief service interruption
Terraform resource addresses must be known at plan time, making it challenging to create rules that depend on resources being created during apply and at the same time are not replaced needlessly when something else changes
When Terraform rules can be successfully created before being destroyed, there is no service interruption for the resources associated with that security group (unless the security group ID is used in other security group rules outside of the scope of the Terraform plan)
The Importance of Keys
If you are relying on the “create before destroy” behavior for the security group and security group rules, you can skip this section and much of the discussion about keys in the later sections because keys do not matter in this configuration. However, if you are using the “destroy before create” behavior, a full understanding of keys applied to security group rules will help you minimize service interruptions due to changing rules.
When creating a collection of resources, Terraform requires each resource to be identified by a key so that each resource has a unique “address” and Terraform uses these keys to track changes to resources. Every security group rule input to this module accepts optional identifying keys (arbitrary strings) for each rule. If you do not supply keys, then the rules are treated as a list, and the index of the rule in the list will be used as its key. Note that not supplying keys, therefore, has the unwelcome behavior that removing a rule from the list will cause all the rules later in the list to be destroyed and recreated. For example, changing [A, B, C, D] to [A, C, D] causes rules 1(B), 2(C), and 3(D) to be deleted and new rules 1(C) and 2(D) to be created.
We allow you to specify keys (arbitrary strings) for each rule to mitigate this problem. (Exactly how you specify the key is explained in the next sections.) Going back to our example, if the initial set of rules were specified with keys, e.g. [{A: A}, {B: B}, {C: C}, {D: D}], then removing B from the list would only cause B to be deleted, leaving C and D intact.
Note, however, two cautions. First, the keys must be known at terraform plan time and therefore cannot depend on resources that will be created during apply. Second, in order to be helpful, the keys must remain consistently attached to the same rules. For example, if you did the following:
rule_map = { for i, v in rule_list : i => v }
Then you will have merely recreated the initial problem by using a plain list. If you cannot attach meaningful keys to the rules, there is no advantage to specifying keys at all.
Avoid One Terraform Rule = Many AWS Rules
A single security group rule input can actually specify multiple security group rules. For example, ipv6_cidr_blocks takes a list of CIDRs. However, AWS security group rules do not allow for a list of CIDRs, so the AWS Terraform provider converts that list of CIDRs into a list of AWS security group rules, one for each CIDR. (This is the underlying cause of several AWS Terraform provider bugs, such as #25173.) As of this writing, any change to any element of such a rule will cause all the AWS rules specified by the Terraform rule to be deleted and recreated, causing the same kind of service interruption we sought to avoid by providing keys for the rules, or, when create_before_destroy = true, causing a complete failure as Terraform tries to create duplicate rules which AWS rejects. To guard against this issue, when not using the default behavior, you should avoid the convenience of specifying multiple AWS rules in a single Terraform rule and instead create a separate Terraform rule for each source or destination specification.
rules and rules_map inputs
This module provides 3 ways to set security group rules. You can use any or all of them at the same time.
The easy way to specify rules is via the rules input. It takes a list of rules. (We will define a rule a bit later.) The problem is that a Terraform list must be composed of elements of the exact same type, and rules can be any of several different Terraform types. So to get around this restriction, the second way to specify rules is via the rules_map input, which is more complex.
Why the input is so complex?
The rules_map input takes an object.
The attribute names (keys) of the object can be anything you want, but need to be known during terraform plan, which means they cannot depend on any resources created or changed by Terraform.
The values of the attributes are lists of rule objects, each representing one Security Group Rule. As explained above in “Why the input is so complex“, each object in the list must be exactly the same type. To use multiple types, you must put them in separate lists and put the lists in a map with distinct keys.
Definition of a Rule
For our module, a rule is defined as an object. The attributes and values of the rule objects are fully compatible (have the same keys and accept the same values) as the Terraform aws_security_group_rule resource, except
The security_group_id will be ignored, if present
You can include an optional key attribute. Its value must be unique among all security group rules in the security group, and it must be known in the Terraform “plan” phase, meaning it cannot depend on anything being generated or created by Terraform.
If provided, the key attribute value will be used to identify the Security Group Rule to Terraform to prevent Terraform from modifying it unnecessarily. If the key is not provided, Terraform will assign an identifier based on the rule's position in its list, which can cause a ripple effect of rules being deleted and recreated if a rule gets deleted from the start of a list, causing all the other rules to shift position. See “Unexpected changes…” below for more details.
Important Notes
Unexpected changes during plan and apply
When configuring this module for “create before destroy” behavior, any change to a security group rule will cause an entirely new security group to be created with all new rules. This can make a small change look like a big one, but is intentional and should not cause concern.
As explained above under The Importance of Keys, when using “destroy before create” behavior, security group rules without keys are identified by their indices in the input lists. If a rule is deleted and the other rules move closer to the start of the list, those rules will be deleted and recreated. This can make a small change look like a big one when viewing the output of Terraform plan, and will likely cause a brief (seconds) service interruption.
You can avoid this for the most part by providing the optional keys, and limiting each rule to a single source or destination. Rules with keys will not be changed if their keys do not change and the rules themselves do not change, except in the case of rule_matrix, where the rules are still dependent on the order of the security groups in source_security_group_ids. You can avoid this by using rules instead of rule_matrix when you have more than one security group in the list. You cannot avoid this by sorting the source_security_group_ids, because that leads to the “Invalid for_each argument” error because of terraform#31035.
Invalid for_each argument
You can supply many rules as inputs to this module, and they (usually) get transformed into aws_security_group_rule resources. However, Terraform works in 2 steps: a plan step where it calculates the changes to be made, and an apply step where it makes the changes. This is so you can review and approve the plan before changing anything. One big limitation of this approach is that it requires that Terraform be able to count the number of resources to create without the benefit of any data generated during the apply phase. So if you try to generate a rule based on something you are creating at the same time, you can get an error like
Error: Invalid for_each argument
The "for_each" value depends on resource attributes that cannot be determined until apply, so Terraform cannot predict how many instances will be created.
This module uses lists to minimize the chance of that happening, as all it needs to know is the length of the list, not the values in it, but this error still can happen for subtle reasons. Most commonly, using a function like compact on a list will cause the length to become unknown (since the values have to be checked and nulls removed). In the case of source_security_group_ids, just sorting the list using sort will cause this error. (See terraform#31035.) If you run into this error, check for functions like compact somewhere in the chain that produces the list and remove them if you find them.
WARNINGS and Caveats
Setting inline_rules_enabled is not recommended and NOT SUPPORTED: Any issues arising from setting inlne_rules_enabled = true (including issues about setting it to false after setting it to true) will not be addressed because they flow from fundamental problems with the underlying aws_security_group resource. The setting is provided for people who know and accept the limitations and trade-offs and want to use it anyway. The main advantage is that when using inline rules, Terraform will perform “drift detection” and attempt to remove any rules it finds in place but not specified inline. See this post for a discussion of the difference between inline and resource rules and some of the reasons inline rules are not satisfactory.
KNOWN ISSUE (#20046): If you set inline_rules_enabled = true, you cannot later set it to false. If you try, Terraform will complain and fail. You will either have to delete and recreate the security group or manually delete all the security group rules via the AWS console or CLI before applying inline_rules_enabled = false.
Objects not of the same type: Any time you provide a list of objects, Terraform requires that all objects in the list must be the exact same type. This means that all objects in the list have exactly the same set of attributes and that each attribute has the same type of value in every object. So while some attributes are optional for this module, if you include an attribute in any of the objects in a list, you have to include that same attribute in all of them. In rules where the key would otherwise be omitted, including the key with a value of null, unless the value is a list type, in which case set the value to [] (an empty list), due to #28137.
Join the Quick Start Waitlist
We can only provide this incredible service to a limited amount of companies at a time. Please enter your email below to join the waitlist and receive updates on what we’re up to on GitHub as well as awesome new projects we discover.
We publish a monthly newsletter that covers everything on our technology radar. Receive updates on what we’re up to on GitHub as well as awesome new projects we discover.