There we go.
All right, everyone.
Let's get the show started.
Welcome to Office hours.
It's January 15th.
My name is Eric Osterman and I'll be leading the conversation.
I'm the CEO and founder of cloud posse.
We are a DevOps accelerator.
We help startups own their infrastructure in record time.
By building it for you and then showing you the ropes.
For those of you new to the call the format of this call is very informal.
My goal is to get your questions answered.
Feel free to unleash yourself at any time if you want to jump in and participate.
We host these calls every week will automatically post a video recording of this session to the office hours channel as well as follow up with an email.
So you can share it with your team.
If you want to share something in private.
Just ask.
And we can temporarily suspend the recording.
With that said, let's kick it off this Office Hours.
So here's some talking points.
I put together one announcement I'd like to make.
Just today.
I think hashi corp. announced that the Terraform providers are going to be distributed as part of the Hasse corp registry.
So this is like what is available today with Terraform models.
The caveat here is right now, it's only official providers they are working to open it up to third parties and other providers to publish their providers.
I guess for the security implications of this.
They're just being very careful about how they go about that.
Anyways, this exciting news because anyone who's tried to use third party providers.
It's been a real pain.
So if in the near future, they fixed that I'll be very happy.
Another public service announcement.
We said this last week.
Just want to share it again, because I'm pretty sure it's a bunch of companies are going to get bit by it.
The root certificates that effect RDS are raw and documents are expiring in March.
If you're using certificate validation with your instances that's going to break unless you improve upgrade your certificate bundle for those instances or fruit for the nodes that your clients run on those certificate bundles need to be updated.
All right.
So the next thing we have a question from here in our community posted and office hours.
He has also some feedback because he asks in Cuba and Eddie's office hours and got some answers there too.
So we'll see how that reconciles with what we recommend.
And then a demo.
If time permitting, we wanted to do this last week we ran out of time.
I just want to show you how we've been able to use CloudFlare as kind of like this Swiss army knife reverse proxy port injecting H2 MLC ss into sites that we don't necessarily control.
All right, let's start with you here.
So the question you'd asked was how to provide a module or a tool to our application developers to provision the databases for them, including the deployment of the secrets inside of communities and in office hours hours right now in that channel.
If you check.
There's a link there to a Terraform repository where it looks like you started kind of like EPBC with putting something together.
Well, it's basically for me, it's in our infrastructure as code repositories right now.
And we want it to or would like to move SAP basically to the application developers.
This is a private project of my the similar is pretty similar to the infrastructure that we use at work.
So you would go to the committee you just have modifier telephone from file.
Yeah, this is Bono.
All right.
That's another one for post.
I think Costco's Hamilton fire down on the bottom.
So easily these two would be one file and we could give this to our application developers.
And I can just maintain those and currently we get roughly around 2 to 10 requests for requests on our infrastructure scope repository and make some people.
And we still have our own people.
So currently kind of gets to the point where it's cumbersome to maintain all these requests and we were thinking about just like putting it out.
So I asked the same question in the communities office hours where a lot of knowledgeable people on.
They basically said, well versed in their developing experience because the environment is either.
So I don't know much about op's application therapy in general.
And yeah it just reduce their productivity from the application developers, because I didn't know the centerfold.
That's the feedback that I got from them.
But I'm happy to know what if you are doing something somebody.
So there's two things at stake here.
There's one is kind of like your stated approach or objective that you're trying to do right now.
And this is one way to do it.
What you describe here is kind of like how I would automate the production of perhaps your production grade backing services for how low to fire for those of you who don't know how notify or is a project that year working on.
It's a helm.
It's a tool to visualize differences between helm releases or helm charts.
And here is kind of like some of the infrastructure code to deploy that.
So what we have here is some Terraform code that provision that generates some random secrets that provisions a post gross role in the database, and then writes those secrets that were generated into Kubernetes into a specific namespace with those values, including the database, you or I in this case is what he's writing there.
So hold that thought doing this and Terraform is great.
And at some point, you're probably going to want to do that like for your production grade services.
This is what you're going to do.
Well, we don't recommend though, is for preview environments or pull requests environments or what we sometimes call unlimited staging environments.
We want to use Terraform in this case in this case.
Well, we would be using is as part of your helm chart you would have the ability to enable backing services that that chart depends on.
And then that makes it very easy to spin up a fully self-contained environment within Kubernetes just by deploying that chart into a release that.
Then the chart itself can generate those random passwords using the Rand function, whatever it is in home templates and it's easy.
OK So that solves kind of like I think the problem actually that you're trying to address right now.
But it doesn't solve kind of your initial requests like, how is this the right approach that we should take for safe production environments.
If I reframe your question.
And so that was the way I first, they actually interpreted it when I was senior question and it's something that we've been thinking about to a cloud passes like, how can we move the dependencies for backing services of your applications that we need to provision with Terraform closer to the applications themselves and not in like some centralized infrastructure repository.
Because you don't want to have to open one PR in the infrastructure repository like most companies have.
And then another PR free application coordinate that whole process.
Right the main problem because we only on regulatory push our infrastructure is cut to production or even to staging and application developers might be faster than us and want to stay up as a service to staging already.
And they have to wait for SRV to dodge a gift with a message.
That's a good point.
One that I didn't bring up.
So you're also talking about not existing cert not just existing services, but also net new services that are deployed.
What's that process.
Yeah OK.
So be the approach that we are starting to lean towards.
But I can't say that we have fully achieved it.
I think there's some others here on the call that have maybe Dale has done it or Andrew Roth maybe if he's on.
But would be to have the Terraform in each one of your microservices.
You have a Terraform application folder in there and that would have the deep.
Backing services that it needs.
Now what you describe here.
Yes, this is a perfect application of what you just what you have in here.
This should be captured inside of a Terraform module.
And then that module will be version separately and of itself.
And then you might want to have some automated tests related to that separately.
But then when you want to instantiate that.
How do you do that.
Well, that's where you're now in your application full.
Now in your applications repository let's say how modifiers your application repository there'll be a sub folder in there called Terraform and that's where you're going to invoke that module as part of your ICD pipeline.
The question is then what do we do about the integration secrets.
How do we get those there.
So that's going to work well in this case is that depending on what you're using for your CI/CD I'm going to say, let's say you're using Jenkins if you're using Jenkins it's going to use the standard credential store and then your pipeline will indicate that that's the credential store, it's going to use.
And then it can just go ahead and position this stuff from scratch.
But the challenge is if you have some credentials that can be programmatically generated and some that needs to be user generated.
That's the challenge.
And that's very often the case like you're integrating with third party guys and you developing a new service.
How do you get those secrets in there for the first time.
I don't have a brilliant answer for that.
We usually just see people kiddos in as part of that cold start.
Well, this kind of stuff your itself with time from very able.
We just put them in well.
And just put that very terrible variable in top secret configuration.
So that's how we do this kind of stuff that's almost an.
And then that also empowers the developer to set that environment variable in your CI/CD.
OK Yeah.
So this is how we do.
We are doing that or they are using basically the services and just to jq and try to get it somewhere else.
For example, Google Maps.
Someone wrote a best script to generate Google Maps secrets.
OK I don't have Terraform support.
But yeah if someone has ideas about us.
I would be super happy to know how you are doing this kind of stuff if you're doing it.
Mm-hmm It's more like exploratory right now.
So also I'm curious.
I mean, anybody interject in the answer I gave is was there some disconnect I missed there, which is the part that you're struggling with.
It's more like I wanted to know if people are already doing it and what our experience was with it because, well, that's the feedback that I got from the committee's office hours.
Yeah, I tried it.
And developers didn't understand why I'd now have to approve infrastructure as code as part of their deployment process.
So I had to prove they did it this way.
They approved basically the terrorism plan and the terror from Kenya to execute it.
And then the application promotion got executed.
And larger.
So you doubled your approval go gates because they moved to infrastructures called into I think it's going to largely that the organization culturally how they approach it.
I kind of react to that.
I this is this kind of like, oh keep other people's problems as it relates to code reviews.
I kind of reflect that.
Don't you want to grow you know like career wise and learn these things.
And I think requiring code owners in your repositories so that certain when certain files are changed that an approval comes from one of those people.
I think that's a way to mitigate some of that.
But that can be all bundled into the same code review process.
Perhaps it slows it down a little bit initially.
One other thing I wanted to say is.
So the challenge here is that we're spanning tool sets.
Right like if all of this works just through coo cuddle.
So to say or like the Kubernetes API it be a little bit easier versus here where I'm sorry.
Go ahead.
I'm saying long held versus here what we're doing is we're straddling tool sets we're straddling a Kubernetes tool set and Terraform toolset for deployment.
And this is where I think that now.
Now, if we look in this repository you're technically using Digital Ocean so it's a little different here.
Yeah And some of our answers would be probably more obvious focused.
But this is where the e.w. s service operator is also, I think, really exciting is the ability not necessarily this project.
But this technique.
This badges.
So you have a Cuban ID.
Oh, interesting.
It's been archived.
But basically, you have a CRT that you deploy that defines that part of the infrastructure.
So that you can stick within the same toolset to deploy.
That's cool.
I actually today found cube farm, which basically gives Cuba need to see ID for telephone providers.
I posted in the office also.
Oh, I will not exploit get net but I think it could also off my issue where I said, it's a second link not the first one where people now see I want to switch, or maybe it's the same coupon coupon looks like this is they've gotten a lot more in.
Yeah, I guess I have not seen this one because ranchers started with one as well.
You know.
Yeah Yeah.
I have not tried it out yet, but it seems like you get a C see d for your telephone providers and can then do the same stuff.
Mm-hmm Yeah Q4, they also do this.
Let me double check the OK.
So it is just I thought Jim form did more than Terraform but OK.
Never tried it yet.
So I. Just want it today like a couple of hours ago.
But I will take a look into it as anybody kick the tires and in Q4.
Yeah nice.
That is the first one she heard about it.
Yeah or it was this based from the one from Capgemini or is that a for I'm not sure.
I did not investigate too much, to be honest.
Other products as well.
Cute folks keep farmers from like app code.
Yeah Yeah.
That's what it was.
It only went to the website saying absolute they do a handful of things I haven't looked them too deeply.
Interesting looking products.
Yeah, thanks for sharing.
Yeah you nailed it.
That's kind of like what I was thinking is.
I think that's where things are going to get easier and easier.
There's more of this is that we can use communities as the scheduler for everything to do.
Cool well I didn't want to embarrass Dale here a little bit.
Dale just got his certified Cuban his administrator exam K And so pass that.
Congratulations Dale.
Glad to.
Glad you accomplished that.
Great Thanks.
And that means anybody else is serious Cooper related questions, ask Dale any other questions see here got something that chat that someone actually do the Cuban writers application developer certificate.
Oh the.
Now I Katie Yeah.
Is that next on your list.
This one actually came about a little bit.
Maybe I think to go more into the security side of things as well.
Data science.
I'm not sure.
I may be doing them watching.
Yeah by the way Dale posted the resources he used to pass that exam in the humanities channel in suite ops.
Check that out.
Yeah, the first link for Linux Academy really does it good.
Or if you want to brace yourself itself, but the one on you dummy itself actually does this practice test that are pretty spot armed with a set of questions that actually go with it.
So are doing both of them you pretty much cover everything.
I have a question does Michael seem Michael a long time listener.
It looks cold wherever you're at in New York City.
I finally kind of gotten the weeds with this product.
I'm talking about was just started here, which is the rule, you are all service within a code fresh and so you know one of the things I do is I was to create a branch context read your book to create a project.
The project has its share configuration.
So acts like a meadow namespace and then what I'm doing is because we have essentially microservices that need to as an application must not support.
So what I've done is I've used Helen file right to basically install all of the applications as they are from the release branch of the latest basically, from our sort of the next branch of the charts.
Then basically running it again with just a diff image tag.
What have you.
I'm trying to figure out the best way to do that next part do I. I tried to do help while apply with just the you using a selector and with a namespace.
But that would seem to do just it all just ended up being reverting back to all having the same image tag and not like overwriting it with that diff.
I'm not sure how to make it a command line.
I have to write a file.
Unsure about what I needed to do in that circumstance if that makes any sense.
Yeah let me summarize then my own words also add some more context, I think for everyone else.
So see you're using ranchers distribution community rancher.
This concept of projects and you're using code fresh as UCS platform.
You want to create preview environments or like these unlimited staging environments as we call them.
And to do that.
You've defined your entire application architecture inform form as part of multiple helmed charts or releases and all of those charts the releases are in this health file.
And now you're deploying that file as part of your CI/CD pipeline.
And when you build a new image you kind of you want to update that service.
Now, the part or this is the part where I lost you a little bit is the problem like, why don't file apply wouldn't be working for you.
Well, I mean, I think I was running a health file sync at first while I biggest because I guess initially, I'm doing this in the model regrow itself.
Right like so it's not all of the list right now at the moment weren't being published because we still kind of build a pipeline.
So they weren't officially published.
We don't have a version.
I mean, no question when asked the versioning system for this.
I'm trying to figure that out to be able to create canary builds that kind of stuff.
And whatnot with you know I have other tools I use for my libraries that I obviously like NPM libraries that use like auto and semantic versioning, but unsure how to be able to make that work here.
Aside from that what site was a question you asked.
No, I didn't.
So I struggle to see where I didn't understand the problem you're talking about with drifts or patches or things like that.
Were you using tools outside of the home or outside of the home file to do the patching or changing images.
No I mean, you know what I mean.
I just use code fresh to create an image tag.
And then I don't like save that file.
I just kind of pass that as a set you assets as a set to the second.
Like yes I do the home file plan, which applies everything.
And I really do help upgrade with the diff.
You know for the one service that I'm trying to see against the overall and trying to.
I was unsure a what.
Which one to run like Darren helm file sync a second time he'll apply the first time I went.
I'm not entirely clear which I should be running in order to be able to your fly.
It gets to think.
Yeah Yeah.
Yeah, I understand the confusion and so part of the confusion is like hell fire as the tool has been growing really rapidly accepting a lot of cars and things like that.
So sink was the original command that helm file came out with.
But then to kind of more closely aligned with the pattern of Terraform where you have plan and apply and destroy the whole file implement that the same things.
So from what I recall I think helped file apply honours that installed flag inside of your releases so that you can maintain the state of weather services installed or not installed while helm files sink.
I don't believe we'll uninstall services based on that installed flag versus otherwise.
So that's that.
Now what you're doing.
I can't I can't say it's wrong.
Like the two phase apply process.
Well but it's different than what we do.
So what we do is that configuration like 4 4 held file, you would use environments.
For example, in the environments if you like.
You don't want to rewrite that file if you want that dynamic and that can just refer to a go template macro for interpolation function for get in right to get there.
That's exactly what I'm doing actually to be clear.
OK I was doing that itself.
And what I found was just weird stuff like music.
Initially I'd like I have environments like with ephemeral and broad and QA which is where my static aesthetic values live right.
So that's where like you know the main thing is that the image tags is what essentially, I wanted.
All right.
Now, if I tried to float up the end up everything there then everything would have the same very value that I set.
But that just sounds like the schema is wrong if you're held a file.
So like that.
And I'd like, OK.
So not everyone is familiar with how file Alma file is a tool that helps you describe all the helm chart releases that you want to have in your cluster.
And the problem with helm is right that the values file is static.
It doesn't support any templating any interpolation functions.
Anything like that.
So the tool help file came out.
Let you describe now what helm releases you want to have and lets you as a developer kind of define your own schema in the form of what they call environments.
The problem with helm and helm charts is that every Helm chart every developer has their own way of describing how to install this application.
So it looks like a mess when you try and stitch these things together versus the helm file.
Now you can define that schema.
All right.
So in the schema your case, you have somewhere where it says image tag.
But it sounds like you only to find that in one place.
It sounds like when you want to achieve this you want to define the image tag for each service.
In this modern reboot what does difference.
What I'm trying to do for the ephemeral right is not only define I have a default. So falls back to like the next tag.
Yeah which is what we tag everything with.
Once it goes away.
What then I want to override just a single image tag for a single service.
Now what I'm actually doing now because I couldn't figure out how to use it twice.
So I'm just doing the whole file sync on everything.
And then is running the helm itself.
I guess the one released and upgraded that I say.
So Yeah Yeah Yeah like that can work.
Yeah, I think maybe if you're able to perhaps after the call or even during the if we have time.
If you can share some portion of that home file that you have been better at answering.
Also the other day the other concern is that using the next tag while it makes a lot of sense to humans.
It's also really hard to really have assurances of what's running and what we would typically do is we.
So we always tag the images with multiple tags and code fresh makes that very easy.
So Yeah, we may be tagged with next.
But we always tagged with the commit shop and the commit shop.
I'm doing the commission with the code fresh branch normalized thing in front of it.
So yeah.
Which is what my name spaces while I also create a new namespace each thing.
So exact that the image tag is that.
And that's for the federal environment.
And then once it gets promoted to the next environment.
It has that plus the next day.
Yeah, I'm only doing next because it was like, how to like how other than pulling down the latest release from code fresh from the registry.
Once I do that, then it will be that I can use that instead.
So let's see here.
I don't know how I can quickly.
And I go upstairs will pick and go to the computer.
I'm on mobile right now.
OK Yeah.
I don't think of an example.
I can pull up.
Well, the reason we fast enough for this to not waste a lot of time on the call.
I don't mean to bother everybody's questions is probably go while I'm getting upstairs and changing my zoom to the computer.
Sure thing.
Also here.
Are you using helm file as part of your process or not.
Yeah, but not us.
Michael's planning it to do.
So we have basically each application has a helm shots.
And then we have basic infrastructure, which is deployed by hand file.
So basically, our set manage our ingress.
All that stuff was two part time file.
But the other stuff is not thinking about what he's trying to achieve.
I think he could use jq to see which tech is currently report deployed.
And then check basically, if there's a difference.
And then only deploy the same file apply the changes that are actually out there because I think and sync and apply.
Difference is only that there's.
So my understanding if we look at this example of that.
I add here is that you'll have many releases of related to this one monetary one.
One could be bold for example.
And then there's an image and then there's the tag here.
And then he has multiple releases.
So here's bolt and then down here will be another one like refiner.
And let's say he's reusing this syntax everywhere where he has the image required environment variable image tag.
But he has that repeated everywhere.
Then how do you target just want changing the image tag for 0.
Maybe I understand.
So that your problem is that it's not deploying maybe if because you're using the next tag and if you just target one service.
How do you just target that one service to update.
I think the disconnect here is that if you were using to commit shy instead.
And then deploying like refine it with that commit shot.
Then that one will update.
But not the other ones because what you can do is you can combine required and with like a coalesce so you can say like Grafana.
Image tag.
Otherwise default to the default image tag.
So that lets you override individual tags for each individual environment or individual releases.
But I am guessing he is in the staircase right now.
I will I will pause that temporarily.
I'm here now.
Sure can share that.
OK go to office hours.
Was that my thing or should I share my screen.
If we want to let this go.
Yeah, we can.
I'll start right.
I'd rather not you know share my code on a thing because.
OK if you don't mind, I'm sure, you can also just as a reminder, these are syndicated.
Yeah, that's OK.
I don't mind that.
I just you know.
So you see my screen now.
So Here's what I have now.
We have a model repo obviously.
Each of the services up here, and then I just a ploy folder in which case, I have the charts themselves.
Yeah And then I have the releases.
And then I have appetite.
Yeah Yeah.
This is kind of what I'm doing with this right now.
Yep this looks good.
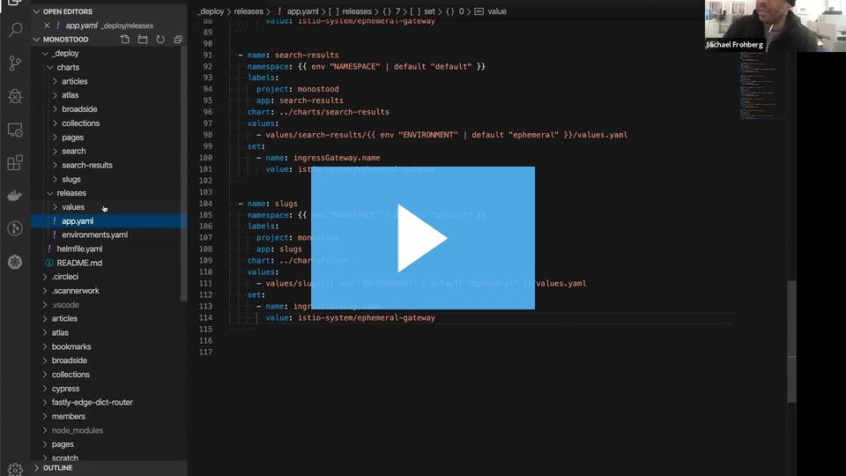
Now show me where the image tag is to find the image tag right now itself would you define for a environment.
Image right now is here.
So define OK next.
And then I override this.
But there's also set in my view, in the chart itself, which is.
Yeah So it's just the that I would do would you want to do this replace line 16 with a go template interpolation.
And there, you're going to look for the value of articles image tag and if articles image tag is empty, then you default it to next.
I would get that by clear.
I'm just doing this right now.
So it would be.
Yeah articles knows the way articles.
No, no, no, no.
So put like required and not require them.
I'm drawing a blank on the exact function name right now.
I think it's getting this.
Or is this just.
OK And not.
And space like this right.
Exactly no.
Yeah, I would stand you know standard environment syntax.
So be or.
Exactly So like that.
Yeah But what I would actually do because you want to surgically target one of your releases not all of you.
So now what I would do is I would change that to be a prefix that with articles image I got it makes total sense.
And then whenever I'm going over something if all value is to be next.
OK So behind idea if you would basically do a pipe and then default next.
Yes, exactly right.
I gotta say.
So the default is here.
That pipe pipe default next is a pipe.
I thought it was the other one I think.
I planning for a pipe.
So sheer pipeline and a string with next guy makes it work.
Yes each of my services in that way, I can.
Exactly So now you can surgically target each one of these with the tag you want to deploy it, which would be in your case, probably the commit shop is right on.
Well, thank you.
I appreciate that.
That's an enormous help because I know that you would do that.
If I do this.
Now I can just run the helm file just once right because yeah you just run it once, then you call start to export or whatever, just set that environment right also.
But to test this, I would just like to just export a ticket image tag and to have high Def and you get a Def and a church only chose this.
Let it change.
Yes it's changed.
So I said export Oracle's image tag.
And then do that locally.
Yeah Yeah.
OK that actually would solve many of issues.
I'm Morgan Brennan to double double the point.
So thanks, guys.
I appreciate that.
So oh come on now stop my share.
But I appreciate it.
You know I was looking forward to this like all week sounds like you finally have it is you that's like hamstringing things that Secretary has a question regarding to get UPS if there's no one.
Yeah, one quick question.
Do I get rid of the initial values that are in charge themselves only use his values.
No you don't.
You can leave those.
It doesn't matter because values that gamble will override whatever you define in those charts.
So if you make your chart something deployable by default, I think that's generally the best practice.
And now what I was doing.
Also thank you.
Next question.
Yeah, I feel that if anyone has any like experiences with pipeline that's code managing with many multiple development teams.
I'm open to hear it.
And I'm at a point now where I'm at, 20, 30, 40 repos and know there's old pipelines code that I have to redo and I'm struggling just working with some offshore teams and they won't let me touch stuff.
They won't accept my peers.
And it's driving me out of my mind.
Well, I'm kind of curious like if anyone's strategically worked around that other than myself.
I'm working on like using outside libraries and some of my pipeline is code and you know you know I keep on thinking I just want to do my own dedicated branch to do that.
You know.
That just seems wrong to me, seems like an empty pattern.
So I'm curious if there's any other.
Experiences out there.
So I can go on talk about it if you want.
So I had this.
I had a similar issue.
We had outsourced one of our projects and the team was really afraid of.
If I do the pipeline stuff and they had a very weird schema.
I think I a similar issue right now, whereas I deployed to production into a branch and has three different benches for environments correct.
Yeah, we are multiple branches we're doing per environment branch at the moment.
So one of the issues that annoyed me the most was that I never knew which features were deployed in which branch.
And so I Justin also had what I was saying goes to mass and we use tick UPS to promote this was the only way for me to manage it.
But also you could have the deployment process in a separate repo and have just updating the array will come across or put up the available talk attacks pushed into a different repo out of the cope update.
And then manage the deployment process in this secondary repository.
OK That's why I'm starting as a viewer toward.
So at least I know I'm not feeling like I'm totally off my rocker and go on that route maybe.
Eric Yeah.
So if I also know that low end under wrath has some experience with this.
I think I might have misinterpreted the original question.
If you want to just restate the problem again.
Well, so I've got a lot of pipeline as code in the repos as it probably should be.
It's supposed to be, and I'm to the point now where I've got several many multiple repos that I'm helping manage as a singular DevOps resource amongst multiple teams and certain teams and projects are more sensitive and they will not allow me to make pipeline changes easily.
It's just seeming like for although I am in a release you know I'm going to try to maintain a cadence with the development teams in some cases.
I need to make changes to their pipelines to energize and improve things.
And then I'll let you know I guess like a better way of describing it.
And it seems like there might be a better way to do so.
OK So they're concerned about changes in flight to kind of these pipelines that could reduce the stability of deployments.
So don't blame them honestly, you know I don't know.
I mean, these things break relative you can break pretty frequently.
OK So one other one other kind of procedural thing or organizational thing is adding code owners right so that when changes to the pipelines happen members of their team that are set as code owners fought for those pipelines have to improve on those changes.
So that's one way to enforce it without disabling kind of like ability to do pipelines as code.
So that's one thing.
And then.
So pipelines.
Yeah, that those themselves have their own lifecycle almost right that you need to be able to validate that that's not breaking things and you have are you are you a what are the common types of changes to the pipelines.
And are those pipeline kit.
Can those changes be validated, but by using preview environments.
And that's the changes that I'm looking at.
So I mean, we put these things together about a year ago.
And there's a voluminous amount of pipeline delivery code and things like that that I personally wrote that I'm not even proud of.
But it was needed at the time right.
Yeah So you they're saying, you know and that is we all know the more could the have and your pipelines the less simple it is and less important is the more it's Yeah breakable.
Right Yeah.
So I mean, you know I'm so I'm trying to simplify things down and make it declarative as possible and going back to some of these old still working pipelines and trying to like remove unneeded elements and things wrong along those lines.
So I am unfortunately stuck in Azure DevOps in this particular case.
But I'll use it to its fullest to do things like pull out pipelines into its own repo and reference that repo externally.
And I greatly simplified a lot of the various repos pipeline code.
But in the same regards I'd point to an outside repo for the code.
So that's better or worse, that's what I'm doing.
But I want to do this more for some of the other for some of the more delicate pipelines and I just I'm just making them tripping up and working with some of the developers on these things and maybe it's just me.
And you know.
But I just wonder if anyone else has dealt with that in any other way.
I keep on thinking, maybe I should just have a dedicated branch for pipeline code you know in each repo that they can't mess with and that sort of strips the control from the team.
And that's not that don't feel right.
You know some way to break other things.
So I don't know.
That's a sort of deep coda.
Are you able or using get up or using another piece.
Yes it's the area of DevOps repositories.
Oh, OK.
I'm not familiar with those.
It is a lot of hassle oh in the audio environments.
OK Yeah.
So the code owners might not apply to that.
Right on.
Maybe you in their branch policies and whatnot that I've been slowly been able to get enforced.
But yeah.
Code owners is they've got something similar.
Yeah, people notify you when there's changes.
But then getting them to approve.
It's a different story.
So what maybe I can have a private conversation with you because it's maybe been over the scope for this conversation or for this talk right now.
But I had an accountant exactly the same issues that you had this application team removed the info as he pipeline stuff that I introduced.
And because I have like 50 to repositories that I'm working on.
Yeah, I wasn't aware of it.
And then they said, well, we are not able to put any more because I restricted the UCLA access.
And yeah.
I wasn't even aware that's a push differently now maybe.
So if you want to 52 plus repositories at the same time right.
Gets hot, especially if you have 120 injured.
Yes stuff.
All of really smart people you know it's not like you know.
Yeah, they'll find a way around things.
Yeah, I'd like to chat you on this.
I appreciate that.
Thank you.
All right.
It's really nice to hear from I I was going to wait to eat or was asking if we were still going to do the CloudFlare demo and I do want to do that.
I was going to give him a second to join here.
I'll get CloudFlare teed up in the meantime.
Any questions.
No, I love puzzles.
Well, I guess if we're just I'm trying to play GitLab on queries and it's going to be publicly facing.
So I'm trying to do it like I wanted to be an exemplary deployment and I've been using their help chart or I should say the instructions for their Helm chart.
And I'm thinking, wait a minute.
There's got to be a better way to do this.
They just seem to be lots and lots of little moving parts.
Like oh you wanted to s three.
Then you got to go over to this demo file and tweak that.
Well, you want to use those three with IAM roles.
Oh, hang on a second.
Now I run it.
So suddenly I find myself trying to configure k I am.
It's just it's not that everyone, or is it just me.
It's not just you.
OK I will.
You'll you'll see all these beautiful demos of my I did.
It's that easy.
But the reality is once you get to like operationalizing something for production, you've got to worry about emeralds.
You've got to get those roles into your services.
You gotta choose if it's like, OK, in this case, you need an S but it'll keep you've got a provision that lucky you got the back.
So that's why we have so much freaking Terraform stuff to support coober neti stuff because there's so much that Cooper needs can't do.
That is like cloud platform specific.
Yeah, this is where you know it's just that we're a little bit early in terms of where things are in humanities but like the operator that terror that cube form that was shared earlier by a peer that looks interesting or like a service operator.
The idea here is that if you can get more of this stuff all in to Kubernetes you're not bridging tool sets.
Yeah then it gets easier because you can have a helm chart that says, hey provision this Terraform code and take the outputs of that and stick it into this community secret.
And then, you know, blah, blah, blah, blah, blah.
Do all this other stuff in Cuban is.
I don't know that many people.
I don't know anyone doing this, though really in production right now typically multiple pipelines that have steps that this part doesn't Terraform this part does the OK robinet is and trying to make this turnkey for net new applications doesn't.
I'll just man up and Yeah, I don't know anybody disagree with what I said there.
I would love to be a rock.
OK So here is CloudFlare CloudFlare workers have gotten a lot of attention CloudFlare workers are a little bit like running lambdas on the edge like AWS lambdas.
I am not like a super expert at doing this stuff.
But I think that's a testament to workers.
But because you don't have to be very hardcore to get a benefit out of it.
So let me go about how we've benefited from using workers.
And I think these are some common problems that others might have too.
So like you know we launched our podcast at a podcast club posse and that's through buzz sprout and buzz sprout offers branded kind of micro sites for your podcast.
Lots of other services do this too.
For example, get review what we use for a newsletter that also offers branded sites.
Thing is how do you have all these different micro sites that they never give you the ability to customize the menu on them.
They never give you the ability to change the CSS on these things yet is your brand.
You want to have control over those things.
So how do you do that.
Well CloudFlare workers makes this pretty awesome because you go over here like to your DNS settings.
And when you set up like the DNS for look load here for a second.
All right.
So let's take a look at the DNS for our podcast.
So here is the podcast.
No, that's the record.
Yeah here's the podcast.
So you see it's a C name to the buzz sprout a year old.
But it's proxy.
So these all requests are going through CloudFlare.
So if I go over here to work here.
I can now set up a rule that says podcast star first goes through this work right here.
And let me just make sure unfortunately, there's no really good secrets management thing here.
So let me just make sure that I'm not going to leak any secrets by opening up this example.
Yeah muted or I hit mute somehow.
Thanks for pointing it out.
All right.
So what we have here is an example of where we're going.
We're rewriting the content on the fly that we get back from the upstream requests from CloudFlare.
So what I'm doing here.
The objective is that buzz sprout.
They offer this podcast stuff.
But they hijack the canonical link.
So that they say buzz Broadcom is canonical for my podcast yet.
I have a branded site that's not cool.
So what did I do.
I just configure the CloudFlare worker to rewrite that content on the fly.
So here I rewrite all a tags linked tags meta tags on the fly when I see these patterns I just replace it with my podcast.
So that it gave me full control over the content there.
Which is cool.
I can also do things like rewrite the rewrite the site map site map XML to 0.2 links in our own site as opposed to their site.
So that was some of the examples there that we did.
Another example.
That's really cool is.
Let's see here, if you need to dynamically install headers like content security policies.
You can do that on the fly.
For example, we're using the Slack in plugin.
So the slack in no JSF for Slack invites.
We could go modify that code.
But then that's just more overhead that we got to do when we just want to do simple things like maybe at the end or so years.
The ability that we can do that on the fly for those requests.
Very simple little script streaming optimizations.
No, I want to go to slack archive redirect.
So many of you run single page application space you deploy those to service like s three, you're limited in what you can do.
So if you wanted to do a redirect it's maybe a little bit harder to do so very kind of pattern is you have a stub file that has a metal refresh equip in there and that made a refresh does the redirect but that kind of sucks because you first see a blank page and then redirect and it's not good.
So here's an example where we fetch the upstream.
And then look for that tag.
And then we do a rewrite automatically at 301 and serve that back to that.
We see that rejects matches.
So that's how we split up our outside.
We actually see the console logs.
Can you see someone somewhere.
Or so.
Yeah So what's cool is the way they've done it.
I mean, if I go here to I got a change domain.
In this case sweet UPS and then go to.
So here's this route I've configured everything to go to slack.
Archive redirects I can launch the editor.
I'm going to open up a slack archive redirects I'm going to go to that domain here.
Mobile are still all the console logs and everything.
My debug output I see here.
OK So this makes it really good that you can just iterate very quickly, you can update the preview as you're updating your code here without deploying it and seeing it.
So it's a safe kind of developed mode.
The downside is they don't provide any access to logs period.
Cloudflare it's not a server.
So what you got to do is you gotta integrate this century or some other third party service where you can basically post your exceptions in your log events and stuff to some third party service be related to this.
There's another similar feature that's existed in CloudFlare for a long time.
But it was implemented using workers.
I believe a behind the scenes.
But not now.
I'm just truly in love with it for these reasons.
So if we go to apps.
They have a marketplace on CloudFlare with all these hacks.
It's like a marketplace of hacks like the different blades of your Swiss army knife and there's a few in here that are really special.
So if I go over to install apps one is you can inject a site.
Now onto any page, you can add CSX onto any page, you can install a Tag Manager on any image, you can add each email to anything age.
So you can see how you can really do anything you want at this point with any page any site that's part of your network.
So like if I go now to cast that cloud posse I have a navigation menu here that's not provided by them.
That's provided by CloudFlare that drops me over to the newsletter.
Would you look at that.
I got a navigation menu that's not provided by them as provided by CloudFlare.
So all these things.
Let me stitch together all these different properties provided by different services that micro sites and get review.
They had a really bad CSX problem that made the stuff look like doesn't look beautiful.
Now Don't get me wrong.
But it looks atrocious before.
And I was able to inject mounts yes to clean this stuff up.
That's called the vertical wow.
This is amazing.
Yeah So CloudFlare is pretty rad in that sense.
But there are other examples.
I'm not going to say names of services that do this, but there are certain sites that can go to a pay up if you want to have a branded hostname.
Not anymore.
If you use CloudFlare you can change the origin of your requests and you can serve it under any domain you want on your site.
So you can do your own branded versions or micro sites of services like that.
Oh, wow.
This is under the free offering too.
Yeah you basically.
And distinctly CloudFlare.
I mean, God bless them you know, they are really fair in their pricing it's not that they have also overage pricing.
So you can start for free.
And then they have a reasonable rate that you can pay per million requests or something like that.
I hate these services that require you suddenly to you go from spent $50 a month.
Then they want a one year commitment at $1,500 a month.
How does the basic fee and compare to front say that when we're done.
It's just a basic TDM capabilities.
How does that compare it to something like we crowdfund.
Well, so this cloud front is pretty easy to beat that.
That's probably the worst CDM functionality wise that I've used.
Now it's gotten a lot better with the edge lambdas on cloud front, but the fact that any change you make to cloud front takes like 30 minutes to propagate.
That's a massive business liability right.
Like oh, we made some mistake an honest mistake.
OK this is down for 30 minutes.
I don't like that was pretty rad with CloudFlare is changes take seconds or less.
Most of the time.
And they manage it to Terraform or manually.
I confess we personally are not for these things.
But CloudFlare is investing a lot into their Terraform providers.
And I believe a lot of this stuff can be done with their form.
They also have a command line tool I for get what it's called, but they have a command line tool to manage this stuff and be more command line driven perhaps somebody can correct me maybe.
But I don't believe CloudFlare has scoped API keys.
And that's kind of like scary.
So Stephen Dunn fought for companies that want to use Terraform with CloudFlare and control kind of the blast radius of changes is you can actually use proxies with Terraform right.
So then there's a company called b.s. very, very good security and very good security is pretty rad because they'll be your man in the middle proxy and that you tokenized is basically that request.
You can use dummy credentials.
And you can scope requests to certain parts basically certain API endpoints.
And it will inject the tokens only for those requests only from IP is that you want only using credentials that you set and those credentials.
If x still traded or leaked are useless to anyone else.
So Yeah Terraform with very good security and CloudFlare is kind of like the pattern there.
We're almost at the end of the hour here.
So I'm not going to do a demo of this, but it's interesting.
We can do something arrange it a better demo of this.
The idea here is like you can create a route for like API that GitHub you can whitelist a certain IP range.
And then when these conditions are met.
For example, the path is such and such, then you can do replacements on fields in that request.
And since most service most things support the HP proxy convention, then you can just have this happen transparent.
All right Erik do you know anything about the kind of phone data protection laws that go into effect beginning of the year.
The GDPR stuff.
Well, I don't know how you call it in California.
But I think it is the equivalent of the same.
Yeah, we haven't been doing that much.
We haven't yet.
We haven't you know buy our customers been asked to help them with any of that stuff too much.
The cool thing, though, is with CloudFlare you can implement that across the board automatically.
You can install those retarded little pop UPS.
You have to have now on sites that say we're exporting cookies as if you didn't know.
And those cookies store information.
Well, with this if they click No CloudFlare can automatically always drop it.
So you can't track them.
Yeah There's some issues.
A bank in Germany implemented Taillefer last weekend and didn't update the data processing agreements on the back page and didn't inform the customers because they're around the details attack and basically counter.
They did so as to ask termination thing.
And now all the customers are pretty pissed off because they gave closure over all their banking information.
But that's the thing that think that happen happened Germany, and it's a pretty big GDP violation when it did, they screwed up the cash rules.
So they were cashing private data or not.
But I think just we'll see initial things that happened.
But they didn't inform the customers that there is now a middleman.
You have to do.
You have to have data processing agreements with the companies and they have to be accessible for your end users.
Yes And they did not do that.
And yet.
Now that 30 is that is really interesting.
So I don't know.
Yeah somebody else is using CloudFlare and you can share more information about that next time.
Maybe it really is.
All right, it looks like we've reached the end of the hour.
And that about wraps things up.
Thanks again for sharing.
I've learned a lot this time and that some others got the problem solved.
So that's pretty cool caught a recording of this call will be posted in the office hours channel.
We'll also be syndicating it to our podcast.
So see you guys next week same time, same place.
Thanks a lot.
All right.