
1 min read
Here's the recording from our “Office Hours” session on 2019-12-11.
We hold public “Office Hours” every Wednesday at 11:30am PST to answer questions on all things DevOps/Terraform/Kubernetes/CICD related.
These “lunch & learn” style sessions are totally free and really just an opportunity to talk shop, ask questions and get answers.
Register here: cloudposse.com/office-hours
Basically, these sessions are an opportunity to get a free weekly consultation with Cloud Posse where you can literally “ask me anything” (AMA). Since we're all engineers, this also helps us better understand the challenges our users have so we can better focus on solving the real problems you have and address the problems/gaps in our tools.
Machine Generated Transcript
Let's get this show started.
Welcome to Office hours today is December 11th.
2019 and my mom's birthday.
Happy birthday mom.
My name is Eric Osterman and I'll be leading the conversation.
I'm the CEO and founder of cloud posse.
We are a DevOps accelerator.
We help startups own their infrastructure in record time by building it for you and then showing you the ropes.
For those of you new to the call the format of this call is very informal.
My goal is to get your questions answered.
Feel free to own yourself at any time you want to jump in and participate.
We'll host these calls.
Every week we automatically post a video of this recording to the office hours channel on suite ops as well as follow up with an email.
So you can share it with your team.
If you want to share something in private just ask me and we can temporarily suspend the recording.
With that said, let's get the show started.
I do want to cover some things that we were just talking about before we kicked off the call here, which is on efficient ways to track your time as a contractor.
If you're doing that type of stuff.
But also here's some other talking points.
If we run out of things to cover a public service announcement here it was AI believe that brought it up again and reminded me this morning.
The official hymn chart repositories slated for deprecation in about a year and there's a schedule announced for that which is on this link.
I want to show you our new slack archive search functionality which makes it a whole lot easier to find what you're looking for in the suite office chat we use.
I'll go live for that I want to show our new guest modules for two kinds new managed node pools for each case as a result of the announcements from reinvent and then one of the things Andrew also asked about were like what are the considerations that we take into account when thinking a CIO platform and I expanded this to be set out.
But let's just quickly jump out 2 this thing about tracking time.
What was that cube called that you were talking about.
Andrew it's called time M��ller so you get the app.
The app is free but you can setup.
I think it's got eight sides or six sides or one to three it's got eight sides so you can set up eight different eight different tracking targets whatever they are whether they're different clients Lauren Berman or no I don't.
I didn't buy the I didn't buy the physical device yet but I have.
I'm using the app oh that just lets you quickly tap on.
So I set up I set up three I set up I've already set up three targets one is my one project that I'm on and the other project they run and then the third one is overhead, which is like time that I spend that I can't charge to either project and so I can hit Start stop on any of them as I'm working through the day because I like this morning I started to work I started work today this morning it I don't know a 30 and I spent an hour just plowing through emails and I thought and I stopped myself and I'm like how am I going to charge that last hour that I spent because it was like an email from this place and then an email from this place and like I didn't know.
And so I was like, all right I've heard about these devices and stuff.
So let's look into them.
And so this app is free I'm using it now I'm thinking about buying the actual device because then you don't have to look down at your phone you just pick it up and move it to another face and it automatically sticks with your phone with Bluetooth.
The device itself is like $69 or something but you know hey it's Christmas I wonder if there's some way to integrate that then with either zap beer or harvest directly because we've been using part of this to track time.
Currently, we offer the following integrations toggle Jira harvest.
I call Google Calendar and outlook calendar cool.
And then who was just talking about walking time walking time has come up before it's me Yeah.
So I use it to basically track however my projects.
So Brooke's great but I don't have to do any serious billing.
It's just like OK most of us at a time of day on this project and had to do so.
And so.
So walking time is kind of like self-inflicted spyware for consultants.
It keeps track like what files you're editing what things you're doing so you can back that out to reconstruct your time as well as track your time at the same time.
Well for developers.
It looks pretty good.
Yeah it's as if lots of integrations I mean also into trade.
So if you're emails I think if you're all right I'm there.
But it's a cool program to just track like roughly how much time you spend.
Anyone else try walking time to know mark champ schemes and using that.
Cool well let's shift the focus back to DevOps first I want to see anybody have any questions related to Terraform communities home et cetera.
Well when we jump right into your question, Andrew then you had asked me just before we kick this off kind of what are some considerations that we took into account when evaluating CCD platform and I just jotted down some notes before the call.
So I would forget it.
But before I talk about this I just want to say that when we started working it was like four years ago and yes there was a rich ecosystem of CCD.
Then and I think that ecosystem has 10x since we started.
It feels like everyone's pet project is due inventing US ICD platform.
And that's why more than I could possibly come to evaluate today.
So I think there are a lot of more exciting options available today than when we started looking at things.
And here are some considerations.
I think are basically requirements today.
So everyone can see my screen here one big thing I think is approval steps since most companies still don't feel 100% confident with continuous deployment to production for example, having a manual gate there.
Ideally with some level of role based access controls who can approve it would be great.
Now since we live and die and Slack having that integrated it's a slack to me feels like a natural requirement as well because I just want to whisk it.
I just want to get a team.
When my approval is required kind of like pull reminders does for pull requests shared secrets.
This is like a Biggie for me and one of my biggest complaints about like GitHub Actions is that there's no concept of shared secrets right now.
So when you add like 300 projects like cloud policy and you have to have integration secrets that are reused across all of them.
How do you manage that.
If you have to update each one.
So we end up having to write scripts to manage the scripts that manage the scripts the of.
So scripting basically updating your shared secrets across your GitHub repositories nutcase.
I would rather have an organizational thing where maybe teams under GitHub could have shared secrets.
I think would be a pretty cool way of doing it.
Easy personalization.
I think you get this pretty much out of the box these days when we started circle C I for example, didn't have that.
Now they do circle to other things like easy integration with Kubernetes.
I don't believe for example circle s.I. has this if you're a big time user communities.
I don't want to spend half my pipeline just setting up the connection to the Kubernetes cluster.
I like that just to be straightforward.
So this was one of the pros why we selected code fresh code fresh makes that really easy because it has a bunch of turnkey integrations to the most common systems we'll use.
What else container back steps again.
When we started this was not the standard.
Now this is the standard.
Every CI/CD pipeline basically use the steps backed by containers.
So I think that's fair.
Supporting web hook events from pull requests originating from untrusted forks.
This is a Biggie.
If you do a lot of open source how do you handle this securely.
And the reality is you can't get by like Travis c.I. will run the pipeline if you don't have secrets in it.
But these days you can't do anything without secrets so that's not a fair restriction.
So there needs to be a secure way to do that.
Typically, it's done these days using chat ops where authorized individuals can comment on the pull request and then that triggers some events.
And in the act of doing that will actually temporarily give that pipeline access to secrets that could technically be expo traded but it's a necessary risk to take.
And just set one of those up and one of my open source projects and it was a frickin' breeze.
Q did you do that with code for sure.
Right Yeah.
So Yeah it should be a breeze.
And technically that is a breeze in code fresh.
I will say that I've had a lot of issues.
But I think that's because our account has been grandfathered in through so many upgrades that are our something's wrong with our pipeline.
So we constantly have to reset our web hooks and stuff.
But Yeah, it is technically very easy in code for us to do that.
And then you just look for a slash command or something in your trigger.
Yeah let's call other nation's natural segue into this chat UPS our request.
So like I said there if you trigger everything you want to check on a pull request automatically your you'll quickly fill up your pipelines your integration tests are going to take forever.
So I think being able to do a conditional type stuff on labels and comments it is a requirement from my system.
It should make it easy to discover all open PR so it's easy to trigger this is why things like so Jenkins does this right out of the box.
But we're not out of the box but with what.
I forget what the plug-in is for Jenkins that does that.
You're using that though right.
Get a plug-in.
Yeah Yeah Yeah.
Couldn't fish had this but they just deprecated that view.
So you can no longer see all of them pull requests and re trigger the pipelines for that.
I think this is a requirement because Paul requests have additional metadata and that noted that you can't sit you can't easily simulate that just by triggering the c.I. build on a branch because you lack all that other metadata about the pull request.
So a way to trigger pull requests that way to trigger builds or jobs from all requests is a requirement manually in addition to automatically should support remote debugging.
So this has been one thing like the road for us, for example, that hasn't been a possibility until recently.
Now they've added support for that.
I here really good things about it.
Basically you want to be able to remote exact into any step of your pipeline for triaging because God knows soil tedious to debug things if the only way is to rerun the entire pipeline from beginning to end and not be able to jump in or look what's going on inside of that container circle circles has been on me about that for a very long time.
There's been tricks we've had to use like teammate to get around that in the past.
So making sure that that's possible.
Question for those of you using Jenkins as Jenkins support that with any plugins today.
Now you may be able to reach into a container that you get into a step in a pipeline.
No it's weird I get it.
I'm sorry.
Oh no you go ahead sorry.
What I've usually done in the past.
So right now, I've got a I've got Dr. builds and I'm using the multiple branch pipeline from Jenkins.
Yeah you usually do as I try to adjust if I'm doing multi container builds I'll try and keep it in a format that I can easily recreate it locally.
So you just try to recreate the same bug then money into Jenkins.
And I haven't had many issues there.
There are a couple of nuances with the chicken on plugins but as long as you don't update Jenkins you're OK which isn't always ideal but it's kind of sad reality I guess in open source.
You bring up but you jog my memory for another thing should support local execution of pipelines for debugging.
So this is pretty cool when you want to iterate quickly and be able to trash things is just to be able to run that pipeline through locally code fresh has had support for this for some time now.
I don't know about circle or Travis.
I don't get it.
Actions you can run locally or at least people have come up with workarounds for that.
Jenkins does that support local pipeline executions.
I would run a local instance of Jenkins to do it.
I've you laugh but I've done that and it works fine.
I know it's just I get it and it works.
Given our demographic of who we are and what we do.
But I wouldn't expect my developers to rattle like Dr. Campos up.
Jenkins and then I the integrations for that and then I guess there's I guess we could perhaps elements Della Jenkins you're not running local Cuban edits is not enough.
That's the good conversation to have.
I would love to debate that with anybody else who is and learn from it.
OK Yeah.
I've actually seen a GitHub action to run a local company just inside of GitHub action which model that will give us tonight.
But we're not doing ridiculous in a flattering way.
I mean that's somebody I spent a lot of time around.
Yeah derailing the conversation but we're not doing it yet but we plan on doing using kind k in yen which is Cuban using Docker in order to test.
Right now we are developing reusable helm files like similar to have cloud plus he has a bunch of reusable files.
Obviously we're like our mono chart like a reusable chart or a reusable helm files and files.
And we need to test them.
So our first iteration is just going to be you know smoke test it home file apply and then wait and then help file destroy you know it just if those work successfully then we're going to call the test.
Yeah successful.
So right now we're just going to deploy into our Kubernetes cluster, but we don't want to dirty the cluster with that stuff.
So we're going to use kind always should be really cool for that kind of show before all this is where things like spiral out of control gets worse standard charts it's true but like what if you had a chart that wanted to test external DNS and then you need the you need the iron rule for that.
You know there are limitations.
The charts for the charts we're working on right now are just services like we're working on a GitLab and a Jenkins panicky cook has any links to the most common thing that we end up needing to use Terraform for in combination with like Helm is for the backing services of chart dependencies of which roles or the most common.
Have any of you seen anything that auto provisions roles somehow as part of Kubernetes like a C or D for animals you can use to Terraform Cubans for better I think and Atlantis to do that.
But what about it.
Their form could be exactly the one by rancher.
I guess there's a few now.
Yeah I'm I'm not doing that.
I don't think I would work because of the debug implications of c or D. I think it's a beautiful beautiful in principle what I want is a better way to choose visually.
Basically what I think I would want is kind of like a circle Travis code fresh slash UI kind of for looking at the CRT is executing.
So there's like a window into that system specifically for this year.
This link relates to flux as well.
I haven't used flex firsthand but my understanding is it's also suffers from some of this visibility to debugging things when things go everything is great when it works but like when you're developing things never work.
So how do you do that.
Just quickly finish up the remaining things on this bucket list of things for conservations risky platforms making it easy to tag multiple versions of a Dockery image.
It sounds obvious or trivial but I've seen systems which literally require you to rebuild that image for every tag you want to have.
So being able to add in tags to an image I think is valuable as well.
For example, we always like to tag the commit shop of every image.
In addition to perhaps the release shop.
Not really shot the release tag.
All right.
Moving on let's support pipelines is code.
Basically the ability to declare your pipelines alongside your code itself and then ideally, the ability for whatever system you're using to auto discover those pipelines.
So GitHub Actions is a prime example of that where you don't need to click around anywhere to get those actions it's working.
Let's see should support a library of pipeline or pipeline steps.
So this has also become very popular these days.
Code for ash has their steps library get up actions I think.
Does this really well.
What platform is it that has orbs as that circle you know has orbs.
So that concept I think, is really important.
So related to this and there's few of you on the call using Jenkins.
I know there's.
I know this is possible in Jenkins as well but there's a lot of my senses I haven't heard anybody really talk it up or a lot of people dislike having this central library of like declarative pipelines within Jenkins and that it leads to management or software on the lifecycle challenges and instability.
Is that your feelings as well.
If so can you elaborate on that and what.
Why does Jenkins fail when circle C I put fresh types seed on this so I'll answer that more generally.
Tools that let you do whatever the hell you want.
Fail because people do whatever the hell they want.
I like tools that provide an opinionated way to do something because then it's like this is the correct way to do it.
So do it this way people do.
Jenkins shared libraries in lots of different ways.
Some of them work better than others.
So there is a way if an organization lays down the law on how to do it and stick to that it can work well just like works.
So like I actually just posted a link to some of our job yes.
Code for ethics.
Because a lot of our Jenkins is open source because we have alternate media using our Jenkins please.
Look at it.
But we tried to create guidelines in this is like create pipeline so a lot of it.
Jenkins job yourself lots of Groovy.
We're all soft offers.
You get a lot of let's over abstract our job yourselves so we input classes in Groovy which is super fun.
One of the big issues that we found is before my time here is that it's just like a whole lot of code.
And people like deviate from those.
And as the standards change over time you end up with series a through Z evolutions of it.
Yeah it's hard to keep everything all together.
And that prompted some of our assessments.
When I look I looked at code fresh I kind of rolled it out a little bit.
But we have like an hour ago and a junk c.d. and a Jenkins X 50 halfway spun up and I'm curious because I push my team on being prescriptive.
That's a good thing.
Jenkins X is so prescriptive that you can do it only one way versus Argo Argo underneath Argo.
You can do whatever the heck you want it's an arbitrary code execution job platform.
But Argo seat is a little bit descriptive and only does the c.d. portion of it.
So you guys how do you pick the right amount of prescription.
Example I'll always give is angular versus react no angular has a.
This is the way it should work.
You know it's much more prescriptive react is more do it however you want to do it you know you want to do it in just vanilla JavaScript great.
Do what you want to do it in typescript great.
Do it.
That's the example I usually give.
Not to say that either angular or reactor better than the other.
I'm not saying that but that's the example you should be using.
We as a thread go city and Jenkins back and forth.
And they just announce their deprecating my not that great they just announced that community would be taking over maintenance of the project.
So whatever.
Yeah and we have there's of course the library in Python that Alex is maintaining that's a pile of Python scripts to manage pipelines inside of that you can implement a yellow parser inside of that Python.
So we've had pipelines for a long time.
There's much better ways to do what we did.
But at the time that was what was a good option.
But I'm looking at Argo how you do everything in it manifesto basically.
I'm liking that that format but I'm seeing limitations because Argo city is much more of a narrow focus.
So for us to use it we're going to have to plug and play like six different components instead of with Jenkins X squared, we would have everything all in one.
We have nothing written in angular and everything written in React so I guess we've made the decision that we prefer to have flexibility, but from that analogy but Yeah I'm trying to figure out the right pieces because there's a several parts here considerations that I don't have answers for in our city.
And so it's a very timely discussion because the bank has made sure this was last week.
So I would love to follow up on this.
If you join us in a subsequent office hours on what you find because Argo has been in our kind of evaluation bucket for technologies as well.
One of the things I find like the approval steps I don't find in a lot of these things is a easy thing to implement.
OK Yeah.
Integration was slack.
Pretty much everything does that these days but in varying degrees.
I would like to say I must integrate with slack and have control over the content of the messages.
Basically there's a lot of systems they'll integrate with slack but they just spew generic messages that are kind of irrelevant for half the people.
So being able to target these messages to groups or teams and then also customize what shows up in the messages I think is something important.
And then support get up deployment notifications.
Now we are a get up shop.
We use it up extensively but I get how it has a special dialogue now where you can see where a request has been deployed.
Tying into that somehow I think is a nice thing.
And then lastly on pricing if you're going for a SaaS solution I really think that the solution should be fair to smaller companies not just enterprises support a standard price per user model and unlimited builds.
Basically the product shouldn't limit how much you want to use it and it should provide a reasonable escape hatch for going over those overages without forcing you into an enterprise locked in so that that's my list.
Any other considerations.
I overlooked that since we have a bunch of people here and a lot of those seating experienced that's a show.
Well Yeah it's a lot to ask about medication year well there once that when coach rush doesn't do so hot out because they get behind the wheel only with enterprise enterprise tax enterprise.
Yeah there is a perfect plug for the B SSL wall of shame website again.
What is it what was that.
It's the soda tax or I think Salvia whatever does someone of you know the tool CI/CD de tool that allows you to include the text of the approval step.
Like for example a default see how I'm charged or the terror from plan or something.
I really would love to f but I thought it was part of the question one more time I just did it here.
I would love to have a tool that allows me to see the approval as a terror phone plan in the approvals that like include that text.
Oh Yeah Yeah I get it.
Yeah that would be cool.
So like it slacks to the chair for most simple channel and then there is a approve or reject kind of button below that that'll be really good.
Yeah for example.
I don't mean bit apartments do this really well because they basically collapse below each other and then you take a proof.
Basically you see the step from before that.
So basically you have some contacts in the eyes.
I side one sexy eye it doesn't really badly because if you want to improve you have to do it from a different view than the actual one of the top, which I really, really dislike because let's be honest there's a lot of people that don't really look at their circle see eye to see a single step and just approve because I have to so we have a we have an implementation that we did by hand.
This was some time ago for a code fresh demo.
What's cool about this implementation that we did by hand is it's just using custom steps so it's you could implement this in any pipeline that lets you run containers.
And it does more or less what I think you're saying.
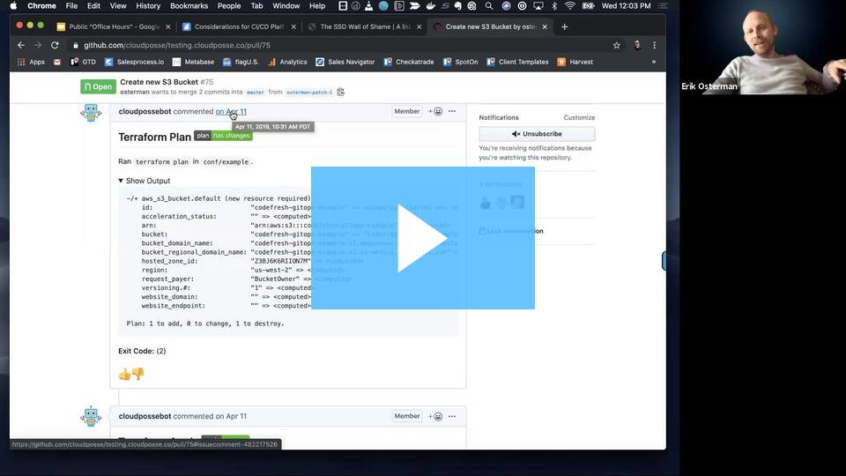
So this looks familiar if you're using Terraform from cloud or Atlantis.
It looks familiar but I think it's a little bit more polished.
And basically what we do is we have we're using the cloud posse GitHub commenter so cloud posse slash get commenter tool and then we have a number of templates that are in this testing that cloud posse dot Dockery reposts if you want to borrow that but then we output this plant.
So I thought this was really clean here right.
This is I feel like it's been a perfect example of what you're asking for.
I would like this now not only as a get up comment but also as a Slack message with the buttons at the bottom.
But it suggests also we stripped out all of my screen hijacked and then and then we stripped out all that superfluous information using scenery.
Now this was done as you can see back in April before Terraform Xerox.
Well I don't know scenery as updated support for Terraform 0 to 12 yet but Yeah.
So then clean output and then just clicking on this or this takes his code fresh and I can approve it or reject it right from here OK.
Yeah that's clean.
I was thinking like how do I approve now from that Because people will in ultimate up on whatever tool you are using and don't see the context.
So you have to kind of force them to actually click on these buttons.
Yeah which I would really follow like actual feet the context of what you are proving is super important.
It is because we never check it out locally and try it.
And we need to.
And then obviously a little bit of reward at the end if your plan is successful or you apply a successful any.
Right it's beautiful.
Thanks Yeah.
Any other considerations.
I left out here in this list afterwards so you guys can use it to form your requirements.
Did you have other platforms like like OS or so this has not been a requirement for us but it's a totally reasonable expectation for others.
You should support multi OS platform.
Well Yeah it's my request is Windows central Android.
We also have AI don't know if this requirement is a good thing or a bad thing but for city who can trigger a rollback from Gucci for example.
So we have a whole bunch of our back access for all of our pipelines.
I find it less helpful than helpful.
But some people require our back.
Yeah e.g. for approval step so I mean that's somewhat related to approval steps because approval steps mean nothing if you don't have our back or a attribute based results.
Yeah I was just trying to figure out approvals steps for our city because in our case here They don't exist.
I have not figured it out but there is a diff in Argo where you can see a difference that could produce manifest files that I haven't actually used it for valuable things.
But it's the only tool that I've seen natively show like every Cuban entity object in a UI where you click on it and see the difference between different places like the like.
Well you should talk to our friend here.
Here he is.
He has something you might like.
And then also help.
Def right.
So are you guys using charts for your releases.
Yeah well while we have helped me it's broken so I looked at home file.
We have some deft deficit and things locally.
However Argo is what templating expanding out the files.
So we're not actually in the Argo PSC which is only where it's not in production right now.
You can't run defgen in production because there's no tiller.
But I'm still sorting all that.
Is where why did you mentioned file in that.
Oh because help file is basically an automation tool around helm and that is and help file requires this to function.
And what I like about it is if you're using held file you basically have a Terraform workflow for dealing with home charts.
So there is a plan phase and an apply phase with a whole file.
But it doesn't.
So I'm currently using files to document what version of what chart is installed for a non application stuff.
So for a chart museum for manager those things.
But it's not working and I haven't bothered fixing it for some that stuff.
So it's not very production ready on that but we are thinking about killing it and moving everything over to Argo or whatever we do for 3D such that you don't have to manage things in cheaper places.
Obviously that would lose some functionality that you're mentioning that the depths of the competitive stuff but trying to understand what the pros and cons of each would be.
Let me also show you one thing that I really love about using a file as part of party workflow.
So we always bring this up like the four layers of infrastructure you have a foundational infrastructure at the very bottom next one up is your platform next one is your shared services and next one is your applications and they're back end services and usually you treat each one of these independently.
So obviously how file works really well for your shared services like the for deploying all the things your platform requires.
Things like external DNS cert manager, et cetera, et cetera.
But it's also really awesome for layer 4 because in our case like so here's our example app where we showcase a lot of the release engineering type stuff for workflows that we use.
If you go into the deploy folder here is an example.
And this shows now.
So this example app has these dependencies and now how file also supports remote dependencies.
So what's cool about that going back to my earlier requirement about supporting like a shared library.
What's cool is you can create a library of services that use applications use and use version settings point to them.
So what I don't like about my example is I'm using local references here but just imagine that these can be remote and then and then inside of the releases folder the developer can define how his application is deployed.
So this is just so it gives the developer declared way to deploy their applications and it becomes even more declarative if you use something like a modern chart which is our chart here and the motto chart is basically a help chart as an interface that you can use to deploy.
99 percent of apps that you're going to be deploying on Kubernetes without needing to write a custom Helm chart.
That's enabled because when you use hell file values becomes your DSL for your declarative interface.
In this case for in your applications.
So since we're systems integrators and we can't we need to be more.
We want to be opinionated but we need to be general enough that it supports all our customers use cases we because we support quite a lot of variations of configuration in our mono chart.
But if you are you building this for your own company you don't need all these variations and you should standardize how you deploy your apps to Kubernetes and then reduce the permutations that are possible there.
Going back to Andrew's comment about if you give everyone the option to do anything, they will do everything.
So you want to eliminate that and this is how you can do that.
So you just have a policy hey you use user use Mongo chart.
Any version you want but that's cool because now you can just look at the interface that you're using of mono chart here.
In this case of version zero 12 et cetera.
So I have to go ahead.
What we want and what we have currently deployed our super different.
But if I focus on what we want and how we think we want it.
This is super useful because I haven't looked at your example I picked off one of our versions.
We Stole a bunch and simple stuff really fun.
Moved away for that tangible stuff into darker and Docker images and set up that you know Travis builds the darker image questions into darker eyebrows here.
Those are all get triggered.
And then at that point there's a new tag on the image, which would then need to go into this chart and get updated.
At first you put the chart in the application repos and we're trying to use a well to the whole formats of how you inherit chart inheritance it's kind of changing around with some of the newer stuff.
So haven't figured that out perfectly.
But do you have an example like this that has like get up set up for when an application change happens and then everything else needs to follow suit.
So yes and no so we also have a.
So here's one nice thing about what we're doing here.
How do I set this up without taking too much time.
So one of the problems I have with a lot of these pipelines that are out there is basically they wake up when they see a new image and then they deploy that image somewhere but that is like one third of the problem.
The other 2/3 is like well what's the architecture that this image gets into.
And then what's the configuration and secrets that I need to run this.
And usually those three things are all tied together.
So deploying an image when the image changes without taking into account those other two things is worthless.
Yet that's how it is demonstrated.
And so many examples out there.
So maybe it works for something people.
I just.
If someone can show me I can't get my head around it.
So our strategy is quite interesting and I call it the helmet cartridge approach.
So I want containers to work like Nintendo video game cartridges and just for the record I mean I stopped playing video games when it was the original Nintendo with Super Mario Brothers.
I so like don't don't ask me more questions about this because I quickly don't know what I'm talking about.
But as really as two days I do.
So I want a Docker containers that I plug into my cluster.
And it just works.
And that means that it basically needs to also habits architecture deployed alongside of it.
So what we've been doing and it's worked out well for the last few engagements that we've done is we bump.
You see this.
This deploy directory is in my application my microservice.
So we're shipping all of this together at the same time.
So this container when we publish it what we can do is we can actually call help file on the help file inside the container and then that deploys the container along with its architecture and image at the same time at a premium.
I don't know I feel like I derailed a little bit there answering specifically or your question there.
Adam So I asked the leading question.
So the appropriate answer.
Yeah I'm still wrapping my head around the right amount because you're right the demos that I've looked at only solid portion of my problem.
Usually the image part of the problem and figuring out how I should thread everything together when there's a million choices is like I can take away.
But I don't know if it's the right way.
So this conversation's helping for me to just think about edge cases that I haven't already thought of.
Yeah so Yeah.
So then this basically answers that.
And so our pipeline for that.
What I don't like about our example app is I did something here that was me experimenting with a way of doing this but I we're not using this particular tool right now for this.
So I had this deploy tool as part of the image that implements like a blue green strategy for the planes container implements a rolling strategy for deploying this container.
My point was more of that is just you see here we're calling Helen file as a step.
And then if you look at the pipeline.
So we ship the pipeline here the example of the pipelines that if you go to the deploy step here here you can see that we are just deploying with Helena file using the cloud tool but you don't need the flights.
Well my point is you could actually just call home file directly.
And that's what we do.
All right.
Let me digress.
Let me pause on that.
Any other questions related to anything we've talked about or something you.
I was going to mention the the the way that most home turds get implemented right now is sad about and that is you know that if you take all the defaults what gets stood up is is like insecure dev.
Oh yes.
Yeah I want to.
I want to start a revolution to flip that you know.
Yeah you forget to set some setting.
You're going to fail up into the more secure space.
You know so that if you set if you don't set any if you don't set any parameters and you take all the defaults what you're deploying is production ready.
I agree with what you're saying in principle.
It's just there's a difference between operationalizing something inaccurate is very different from getting a PRCA and the difference between victory and success and failure is often early quick wins.
So psychologically speaking practically speaking I get why these charts try and be as turnkey as possible that like look in one button.
I get this full on Prometheus monitoring cluster with Griffon and I fully integrate it to everything in wow that was easy.
But yeah operationalizing it is now going to take 80% lot longer because there's so many things and considerations.
You gotta do.
The thing is that if we optimized for the latter which is what we really need to go to production most people would fail because there's so much that has to happen to get it right and it's non-trivial like.
And that's also where you're getting a more opinionated like.
So does that mean we are out of the box require a C So when 99% of the stuff does analysis so and then if you're going to use us.
So how are you going to do us so well.
We use key code you use access somebody else uses whatever this is like the permutations explode that you can't support.
And that's what's so aspirational.
I agree practically.
I just don't see it working.
So the way.
We're coming about it for my team right now because right now we are coming up with hem files that act as we're taking we're taking the approach that you guys have come up with for and maybe you haven't come up with it, but you're using it for your Terraform route modules we're having.
We have help them find root modules where they're literally.
This is the way I want you to deploy production GitLab.
It does require SSL you know and for MVP where we're going to support one sample because that's what we've been doing at first.
We're not saying it requires key cloak.
We're just saying it requires civil rights.
So whether that symbol coming from OK or smoke coming from actor or whatever we care.
Yeah and then what we're doing is saying and this is what I love about him file and I'm learning more and more about him file I haven't used it for that long yet but we're saying we're using the environment's functionality to say the default environment is production and if you say dash dash environment equals dev then it doesn't worry about all that stuff.
Exactly Yeah.
No environments are great for that.
We see people like you.
Let's say we have humility.
I know where we're talking layer cakes here.
Layers and layers and layers.
OK that out of the way.
OK what's cool about health file and environments is environments.
Now let you as a company define the interface to deploy your helm releases, which is in a lot of ways perhaps the final layer.
If you're using help.
This is basically how can we as a company say we want to consistently deploy our apps using Yelp because helm charts have a ridiculous variation on the schema is basically a values no to at home charts have the same interface unless it's developed by your own company.
So help file by way of environments lets you know to find a consistent interface deploy all of your apps that developers can understand.
Yes there are a few downsides to this.
When you want to figure out how to implement a new toggle or whatever you've got to go five layers deep or whatever to figure out where to stick that in that's our predicament right now.
Source leverage.
The goal is like the goal is if one of my people, says helm file apply GitLab and it won't work because it's got required variables but then they add in all the required variables that add that it tells them to add you know because it'll tell them exactly what they're missing.
Once they've added all the required variables and it works it is now the exact prescriptive way that I want them to deploy GitLab which is like oh that's the holy grail right there that is beautiful.
I do like that.
I do like that especially the emphasis you put there on the required variables and that it tells you what you're missing.
For that one thing.
Remember our talking points.
We didn't get through most of them so I'll leave for next week.
One thing I just wanted to point out as it relates to health.
The official help chart repository being deprecated.
There's some interesting discussion brought up this week getting peer you pointed out a bunch of them which is like this is going to reduce the quality of a lot of charts out there because of the lack of automated testing that most people won't implement.
People have different levels of rigor as it relates to maintaining their charts producing the artifacts uploading them not clobbering previous releases.
Basically the ecosystems matter the way their signed packages up there.
There is so many things that go wrong as a result of the official chart repository going away.
Now we all know why that official chart repository sucked.
It was impossible to get a change through because of the levels of bureaucracy and the checks and everything else like that.
So I don't know.
There's a balancing act here.
What I want to point out is one thing is that I think a big part of the success of for example known is that it doesn't require a dedicated repository to manage it.
The fact that you can basically point at any git repository and pull that stuff down and have immediate success I think is awesome.
I think it's a problem that helm has taken this staunch approach that we got to have a managed chart repository which is basically just a glorified HP server.
But yeah why do we need to make it like there are always public source controls and it's been proven to work with NPM.
Why don't we just do something like that.
So the truth is you can using help ins it's non-standard but this is so this is what we've been using now for over a year is the home get a plug-in here that I recommend.
Where is it installed.
So there is a dependency.
This is to install a chart just from a git repo.
Yeah exactly.
We have repo it's this one here.
I'll share it.
I really dig this plugin and it build because I am so good so this plugin withheld file.
You basically have your package.
Jason for 4 Cuban edits you can do also this on the positive I just send in bitch doesn't work with versioning, but you can just specify the URL to the chart.
Which also works you are.
Well, I suppose it's like maybe trying to save Yeah well I get to the tar all but somebody is going to create that will produce that artifact.
Yeah and it works like if you have like a one to one correlation between like GitHub repositories and charts that use the tar ball you were out for the chart and maybe maybe that's actually the answer here is that we should move away from mono repos to poly repos for health charts and then we can just leverage that functionality.
But this is.
Yeah this is imputing up a tarball as a really sort of fact inside your releases.
No no you don't need it because again hub every good hug repo has an automatic Tarbell artifact so it doesn't just go that don't work with the way that would that work with the way that that.
Because when you say helm package like it packages up a turbo in a specific format.
So you would have to have maintain that format on this.
So to say, in the repository it doesn't do anything else so it just zips it up.
So right.
So long as you maintain that format basically the route of your GitHub repo needs to be where the chart became.
Yeah the same format as what it's expecting.
Yeah Yeah.
That could be cool.
I mean it's worked really well for Terraform and tier for modules.
So I think it's probably a good approach for helm charts as well even though so we didn't do that with five possibly charts because we were just emulating what Google was doing originally but now that's going away.
So I guess it's a brave new world.
Well and Google loves model repos too.
Well I don't you know people try to mimic you know their model repo approach and fail at it.
You know there are certain circumstances where it makes sense but you know what makes everything harder.
So let's see here.
So here's an example of a chart.
All you need to do is create a repo called cert like I think maybe to maybe.
So what is it is called Terraform primary provider block.
I think what we should have is probably helping cert manager chart or something or something like that should they.
I think the community should come out with a canonical repository named structure and support that.
Therefore, if you're familiar with the Terraform registry I want to refer back to the x case Casey d.
I posted a few minutes back.
Well there's Maven right.
There's the maiden maybe an object the component library that's also published a prior art in that as well.
A lot of these will have that.
I'm just going to how it works.
I was just going to share this for the terror from module registry that they're very particular on how you name your GitHub repository.
Basically Terraform provider name.
I think we need that for help.
Charts so we get some sanity in the ecosystem.
Is there a similar thing for health hub and how to get something published to help them.
Good question.
It is serious.
It helps set up so you can help people.
So that's a report that gavel in there which works kind of but the quality currently of these reprocess.
Super super super bad.
I mean I get daily notifications of people publishing the same version as the same ditches like this is a mash.
And for me, it's like how can you use that child and not be notified about it and it's still the official help at home which I find super super super risky.
But nobody can have it.
How much does not track source code.
It tracks the package repo where you pub where you push up your tar balls.
Right Yeah.
I just realized Adam I forgot to finish that thought that we were talking about earlier you wanted to see the difference between two versions.
This is what you could integrate with your we've just got to compare.
Yeah here's this is what you could integrate with your solution.
Why am I not getting a diff.
I'm not sure.
Try the other one.
Try not artificially maybe a release will spark some of CJJ.
Images or process to impact mentally.
So they're kind of a reach.
So with you just take on compared and right next to you I didn't get anything they work well we go.
So you compare any two releases of a health chart and see what's changing.
Yeah this would be you bring along something I mean this is a super useful cause like when there's the mondo repos.
There is no you know versions of individual home charts that you can really look at.
So there's a couple of discussions.
I wrote this shot maintainers so there's no enforcement that the shot has to be an open source and I don't have to disclose the source pressing you reproach approach which I find super super stupid because is the asking you or you can just like look at it.
I wrote a recommendation that we implement like files you're in the home that is h like I did with this one Yeah.
But let's see you should probably just get it or you would be interesting if you could somehow partner with hip hop.
It seems like a perfect synthesis of what I'm writing with them but the interest was kind of low.
Really I don't know.
Yeah Yeah.
I wrote a lot of messages for them but the interest seems to be Well I'm kind of there but not really.
Let's see because I would like my opinion like a rapper should be like they should be at least a central not every service like the digits that should be shown upload them but its age should be checked against.
So if you go like at least some kind of checking like it's a great package just being a store to upload them that age and it just changes that you get an alert and they don't see a line.
I agree.
Something like oh Yeah Yeah there's lots of things to do but Yeah let's see whipped cream screen.
I put it there.
What I think is kind of like what should be done but let's see how it goes.
Well all right.
Any last thoughts before we wrap things up today.
I'm starting to get interested in building stuff if anybody like has an initiative going on around that like AWS building.
Yeah all right.
Yeah we should probably dedicate had more time to cost optimization techniques in the US sometime soon.
We pay for courthouse and they have a communities thing that splits open up but we're not billing to different teams because it's more of a let's make sure we don't have a bunch of snapshots that need to get deleted and a bunch of instances that are not right sized.
But I'd also be curious how to apply billing to communities.
It's also all of this stuff to do in get us to.
Yeah Yeah.
OK go.
I'll make a note of that and cover that on our upcoming office hours next week.
All right.
Looks like we've reached the end of the hour and that wraps things up for today.
Thanks again for sharing everything.
I learned a bunch of little cool tricks today.
I'm going to go check out the time tracker thing I always learn so much.
Thank you.
Again the recording will be posted immediately afterwards in the office hours channels.
This is available.
See you guys next week same time, same place all right.
Ms
